


各位好,在今天的議程中,要來談談 JDK8 中,那些搭配 Lambda 表示式的 API 該如何實際運用。

JDK8 在今年 3 月 28 日正式釋出,我知道有些人已經花了一些時間在研究 Lambda 了,不過,在這邊還是先花個十分鐘,很快地概覽一下 Lambda 表示式等元素,這些元素足以讓在座的每個人都能順利瞭解接下來的議程。
我們會透過一個實際的例子,藉由重構的手法,逐步讓大家看到搭配 Lambda 的 API 該如何使用。

真的要談 Lambda 的話,細節很多,你可以在我的網站上找到不少細節資料,因此,接下來 10 分鐘,只會談到最重要的部份。
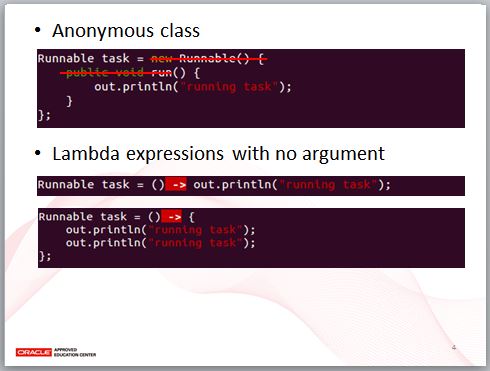
許多人理解 Lambda 表示式出發點是匿名類別,我們也從這個談起,這是實現 Runnable 介面的匿名類別寫法 … 不過,這當中有不少重複資訊,像是匿名類別的 Runnable 名稱、實現的 run 方法名稱等。
去除掉這些資訊,加上箭頭符號等整理一下,就是沒有引數的 Lambda 表示式,編譯器可以藉由等號左邊的 Runnable 知道,等號右邊是在實作它的 run 方法。
如果有多行程式碼的話,也可以使用區塊方式 … Lambda 表示式可以用來替代匿名類別的場合,條件是實現的介面只有一個抽象方法。

依照相同的邏輯,我們可以看到有引數的 Lambda 表示式,如何實現 ActionListener 的 actionPerformed 方法,這邊也看到多個參數的 Lambda 表示式,比方說,JDK8 內建的函式介面 BinaryOperator,實際上 Lambda 表示式實現了它的 apply 方法,如果想要用區塊方式來實現,因為 apply 必須傳回 Long 型態,因此必須明確加上 return … 如果不是區塊方式的話,不用加上 return … 稍後我們還會看到函式介面的簡介。
實際上,因為編譯器可以從函式介面的定義上,或者是泛型宣告上知道參數的型態,因此,在不少情況下,可以省略參數型態,這特性稱為型態推斷,例如,從 actionPerformed 方法簽署可以得知 event 為 ActionEvent 型態,從泛型宣告上可以得知 apply 的參數是 Long 型態,這邊就不用寫出參數型態,讓 Lambda 表示式更為簡潔。

Lambda 表示式就只是一個表示式,不能獨立存在,同一個 Lambda 表示式,必須搭配目標型態,才能決定它是哪個類型的實例,在這邊,相同的 Lambda 表示式,分別代表了 Runnable、Request 型態。
有了 Lambda 表示式,不代表你得到處寫下 Lambda 表示式,這樣很容易寫出重複的 Lambda 表示式,例如,實際上你可能常常寫下這類直接使用了 String 類別 compareTo 的 Lambda 表示式,像這類情況,你可以直接參考 String 類別的 compareTo 方法就可以了。
除了 Lambda 表示式之外,JDK8 也擴充了不少現有的 API,像是 Collection API,為了能在介面上新定義方法,又不破壞既有已在運行的程式,JDK8 的介面也作做了語法演化,允許在介面上定義有本體實作的預設方法,像是 Iterable 上就增加了 forEach 方法,因此,你看到 forEach 方法時,就不用太意外。
對 Lambda 的簡介就到剛剛結束了,接下來,要來正式認識那些 Functional API,這些 API 對於習慣既有 Java 舊式 API 風格的開發者來說,如果又沒接觸過 Functional Programming,乍看之下會有相當大的違和感。
接觸過 Functional Programming 當然對瞭解這些 API 有幫助,不過,沒接觸過也沒關係,接下來,我們會看到,如何透過一系列的重構手法,來認識與使用 Lambda 與 Functional API。

還沒實際使用過 JDK8 的 Lambda 嗎?拿個新專案來試試?實際上,想要開始使用 Lambda 最好的方式,就是從既有的專案開始。
這段程式碼來自《Java 8 Lambdas》這本書,這本書也推薦給各位,我也預計在 8 月中之後著手翻譯此書。
我會以《Refactoring》這本書的方式來重構這段程式碼,而後,套用 Lambda 與相關 Functional API,使用的重構手法不多,就是重構第一章影片出租店的手法而已。
這段程式碼是要找出多張唱片(Album)中,時間長度超過 60 秒的歌曲(Track)名稱,程式碼看來不長,但對我來說,還是有重構訊號,也就是兩層 for 迴圈,這表示一定做了兩件以上的事,為了要將內層迴圈重構至另一個方法,首先必須有歌曲清單。
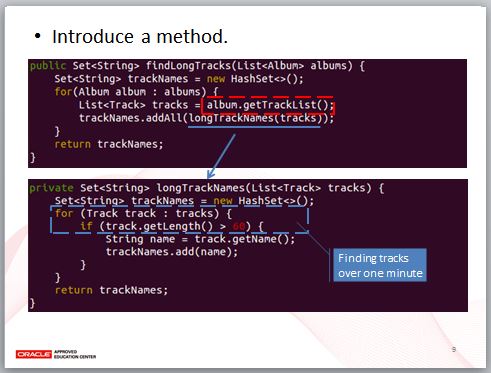
我們取得歌曲清單,傳給 longTrackNames 方法,這個方法會取得超過 60 秒的歌曲名稱,是我們重構出來的方法。
longTrackNames 方法中,一開始會找出超過 60 秒的歌曲,然後再從歌曲物件中取得歌曲名稱,這是兩個動作,我們要再導入方法將之分開。
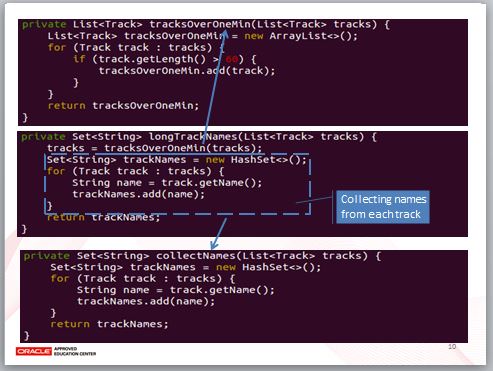
找出超過 60 秒歌曲的方法,我們命名為 tracksOverOneMin,基本上就是只將程式碼提取出來。
這麼一來,原本的 longTrackNames 中,迴圈部份就單純是進行歌曲轉名稱的動作,照例,我們還是將之提取出來為一個 collectNames 方法。
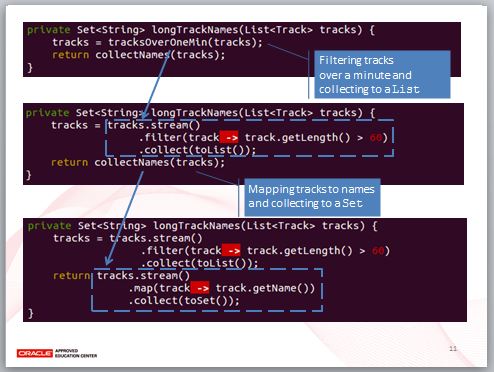
longTrackNames 現在很簡單了。
trackOverOneMin 的作用是什麼呢?名稱上可以知道,就是過濾超過 60 秒的歌曲,然後收集到 List 中,用 JDK8 的 Lambda 與 API 重構,開一個 stream 操作,之後正是「就是過濾超過 60 秒的歌曲,然後收集到 List 中」。
類似地,collectNames 的作用是什麼呢?名稱上可以知道,就是從歌曲取得對應的名稱,然後收集到 Set 中,用 JDK8 的 Lambda 與 API 重構,開一個 stream 操作,之後正是「從歌曲取得對應的名稱,然後收集到 Set 中」。
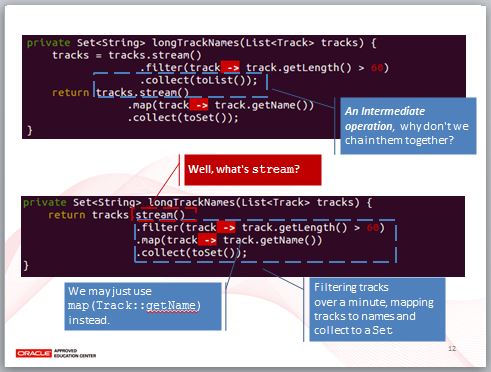
現在,longTrackNames 中有兩條 Lambda 管線操作了,只是,為什麼要收集為 List 後,再重新開一條管線做對應與收集為 Set 的動作?這不是多此一舉嗎?List 不是我們真正要的結果,這類中介操作可以不用,因此,把它們串在一起好了。
實際上,track -> track.getName() 這個 Lambda,可以用方法參考 Track::getName 取代,那麼就會更有可讀性:「過濾出超過 60 秒的歌曲,然後從歌曲取得對應的名稱,並收集為 Set」。
那麼,實際上,開一個 stream 操作,意義是什麼呢?

在 JDK8 的 Functional API 中,Stream API 擔任很重要的角色,許多高階抽象的可能性,都是由它開始。
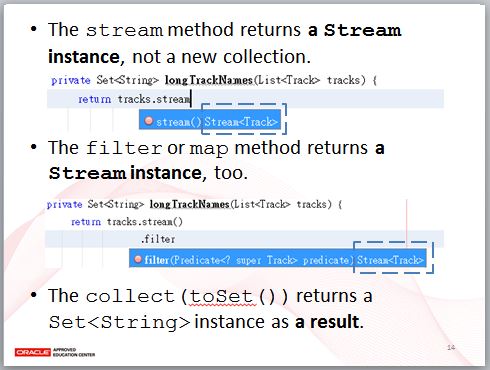
先前看到的範例中,Collection 的 stream 方法實際上傳回的不是 Collection,而是新的 Stream 實例,類似地,後續的 filter、map 方法,也是傳回 Stream 實例,只有 collect(toSet()) 時,才實際傳回了 Set<String> 做為結果。

Stream 實例從來源取得資料,來源可以是 Collection、陣列、產生器函式或者是 I/O 頻道。
Stream 實例上有一些操作是中介操作,也就是實際上呼叫時,並不會直接產生結果,像是 filter 方法產生新的 Stream 實例,但這個 Stream 實例不會包括過濾處理後的結果。
Stream 實例上有些方法是終結操作,終結操作實際處理最後的結果資料,像是 forEach 方法,可以讓你指定 Lambda 表示式,決定每個管線操作的結果要如何處理。
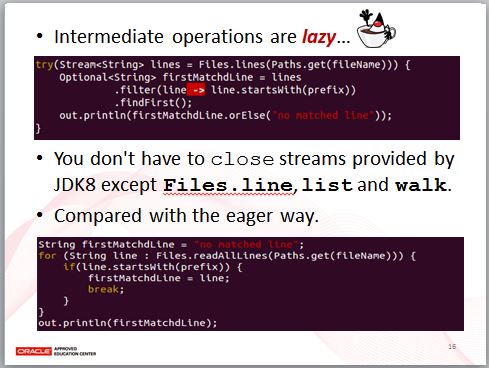
也就是說,Stream 的中介操作其實是惰性的,非到最後關頭不會進行實際的資料處理。舉例來說,Files.lines 方法會開啟一個來源為檔案的 Stream,你可以指定將其中行首為 prefix 開頭的行過濾出來,然後找出第一個符合的行,實際上,filter 方法結束後,沒有任何一行被讀取與過濾,直到 findFirst 執行時,filter 才會開始執行逐行讀取、過濾,如果找到第一個符合 filter 條件的行後就結束,後續的行不會再讀取。
在這邊,你看到 Files.lines 搭配了 JDK7 的 try-with-resources 語法,基本上,JDK8 中除了 Files.line、list、walk 方法涉及檔案 I/O 資源需要關閉之外,你不用特別去 close 一個 Stream 實例。
可以與自行撰寫迴圈的程式碼相比一下,Files.readAllLines 實際上會讀取整個檔案,然後以 List<String> 傳回結果,如果檔案有 1000 行,而實際上你在第五行就找到符合條件的第一行,那麼,這個 eager 的寫法,相對於 Stream 的 lazy 做法,就會比較沒效率。
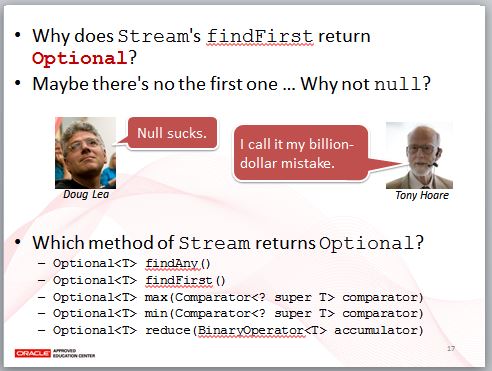
有注意到,剛剛 Stream 的 findFirst 傳回的型態是 Optional 嗎?為什麼?因為也許過濾完每一行之後,沒有符合的條件。
那為什麼不傳回 null?嗯?Java 開發者最熟悉的 Exception 之一 NullPointerException 應該足以解釋傳回 Optional 而不是 null,JSR166 Java 並行 API 領導者 Doug Lea 討厭 null,快速排序發明者、圖靈獎得主 Tony Hoare 甚至說,null 的使用造成了數十億美元的損失。
Stream API 中有幾個方法都傳回 Optional,像是 findAny、findFirst、max、min、reduce 等方法。
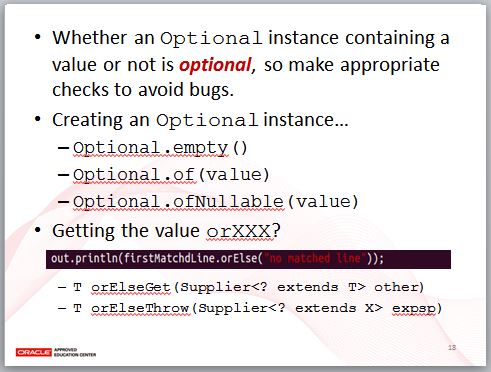
Optional 的作用之一是文件化,如果看到一個方法傳回型態是 Optional,那表示可能沒有結果,因為 Optional 實例中可能包括或不包括值,因此,你要對傳回的 Optional 進行檢查。
當你要從方法中傳回 Optional 時,可以有幾個方式,使用 empty 可以傳回沒有內含值的 Optional,of 方法可以指定 Optional 的內含值,如果你的值可能是有值或 null,那麼可以使用 ofNullable 方法,這通常用來銜接既有的 API 傳回值有可能是 null 的情況。
在想要取得 Optional 內含值時,使用 orElse 方法可以在沒有內含值時,以指定的值作為其傳回值,orElseGet 可以讓你指定其他型態做為替代值,如果想要在沒有值時拋出自訂例外,可以使用 orElseThrow。
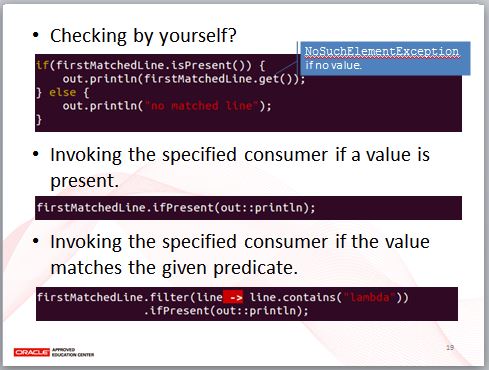
當然,也許你有比較複雜點的檢查與處理方式,那麼可以使用 isPresent 測試看看有沒有值,再於有值時使用 get 取值,如果實際上 Optional 沒有內含值而呼叫 get,那就會拋出 NoSuchElementException。
如果想要在有值時,直接指定處理方式,像是輸出至主控台,那可以使用 ifPresent 的另一個版本。
Optional 也有個 filter 方法,可以用 Lambda 表示式來過濾內含值,如果 Lambda 表示式傳回 false,那麼傳回的 Optional 就不會有內含值。

你可能開始對剛剛看到的一些方法上接受的 Supplier、Consumer、Predicate 等型態感到困惑,先前看過,Lambda 表示式的目標型態,是必須僅具有單一抽象方法的函式介面,有一些函式介面的形式,其實你會經常使用,因此 JDK8 為這些常用的函式介面進行了標準定義,當你需要函式介面時,應該優先使用這些介面,以達到較高的互通性。
JDK8 內建的函式介面,主要可以從四個類型開始認識。
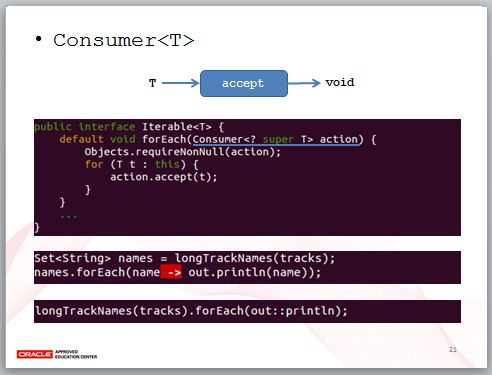
Consumer 顧名思義,就是只消耗傳入的引數,不傳回值,實際的例子就是 Iterable 的 forEach 方法就是接受 Consumer 實例,每個元素逐一傳給 Consumer 的 accept 方法。
實際上,使用 forEach 時,也不需要關心它內部是不是使用迴圈,你只要告訴他如何處理傳入的引數就可以了,像是這邊看到的 out.println,如果能善用方法參考的話,會更有可讀性。
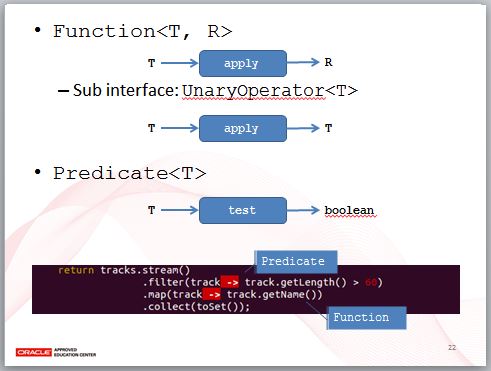
Function 接受 T 型態的引數,傳回 R 型態的值,就像給個 x,傳回 y 的數學函數一樣,因此才命名為 Function。像這樣使用圖來記憶,可以加快你對這些內建函式介面的熟悉,指定 Lambda 表示式時,你只要關心輸入型態與輸出型態,Function 有個子介面,輸入型態與輸出型態都相同。
Predicate 就是使用判斷式的場合,接受 T 傳回 boolean 值。例如,在這段程式碼中,filter 接受的是 Predicate,而 map 接受的是 Function,實際上,在你熟悉這些 Functional API 之後,就不會再去特別留意 filter、map 接受的引數型態了,你只會記得像這邊的圖表示的資訊,注重在輸入型態與輸出型態。

Supplier 不接受任何引數,只傳回值,因此就像個生產者,不過 JDK8 叫它 Supplier 而不是 Producer。
乍看之下,你可能不清楚一個不接受任何引數,只傳回值的 Supplier 可以做什麼,實際上,它主要用於惰性執行的場合。例如,剛剛談過,如果 Optional 沒有包含值,而又被呼叫了 get,那就會丟出 NoSuchElementException,也許你會想要拋出其他例外,此時你可能會想要搭配 ifPresent 的條件檢查,實際上,你可以使用 orElseThrow,你指定的 Lambda 表示式不會馬上被執行,只會在沒有值時才被執行,一樣地,這邊的例子,搭配方法參考或許會是比較好的選擇,對可讀性會有幫助。
類似地,如果想要避免每次都進行 Logging,也許你會像這邊使用 if 判斷,在啟用 debug 模式時,才進行 Logging 的動作,以避免效能問題,在 JDK8 中,Logging API 有些可以接受 Supplier,例如,乍看之下,底下 Logger 的 debug 方法好像會馬上執行,實際上,這是另一個接受 Supplier 的重載方法,只有在 isDebugEnabled 為 true 時,才會執行指定的 Lambda 表示式,清楚易讀,又可以避免效能問題。

Java 中有基本型態與類別型態,為了有更好的效能,Stream API 有專為基本型態設計的版本,想要搞清楚這些 API,透過命名慣例會是比較好的方式。
比方說,針對基本型態的 Stream 有 IntStream、LongStream、DoubleStream,上面有一些針對基本型態的 Stream 方法可以使用。
而針對基本型態的函式介面,Comsumer、Predicate 的前置名稱代表了參數型態,Suppiler 不接受參數,因此,前置名稱代表了傳回型態,至於 Function,因為會有輸入輸出,因此 To 前後的名稱,分別代表了輸入型態與傳回型態。
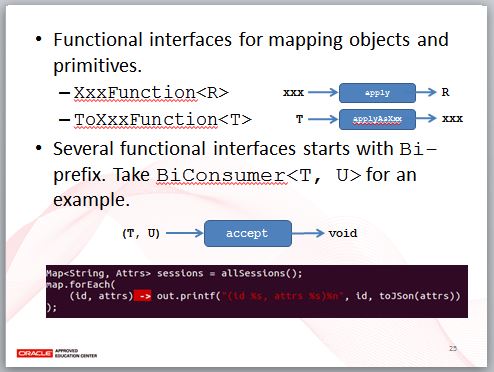
也有一些函式介面,用於物件與基本型態之間的對應,基本上,就是那些有前置名稱,又有泛型宣告的函式介面。
有些函式介面以 Bi 作為前置名稱,表示它們接受兩個引數,舉例而言,BiComsumer 接受兩個引數,Consumer 名稱表示沒有傳回值,實際的例子之一,就是 Map 上新定義的預設方法 forEach,Lambda 表示式會接受兩個值,分別為 Key 與 Value,用來逐一迭代 Map 中的 Key/Value。

接下來看一個 Reduction 的概念,實際上,先前看到的 Stream 操作中,collect(toList()) 或 collect(toSet()) 甚至 findFirst 等,都是一種 Reduction 的概念。
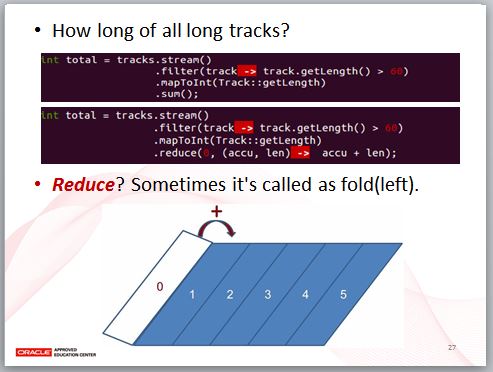
那麼什麼是 Reduction?如果你要取得長度超過 60 秒的歌曲時間加總長度,在 mapToInt 傳回 IntStream 之後,你可以直接呼叫 sum 方法得到。
實際上,你也可以使用 reduce 方法,reduce 是一種內部迭代,第一個引數是迭代的初值,每次 Lambda 的第一個參數接受上一次 Lambda 運算後的結果,第二個參數是當次迭代的元素,以這邊的 Lambda 看到的,是對兩個值做相加動作,結果就相當於動畫看到的,每一次削減掉一個元素,就進行一次相加動作,這也是 reduce 這個名稱的由來,在別的語言中,你可能會看到這個動作被稱為 fold 或 foldLeft。
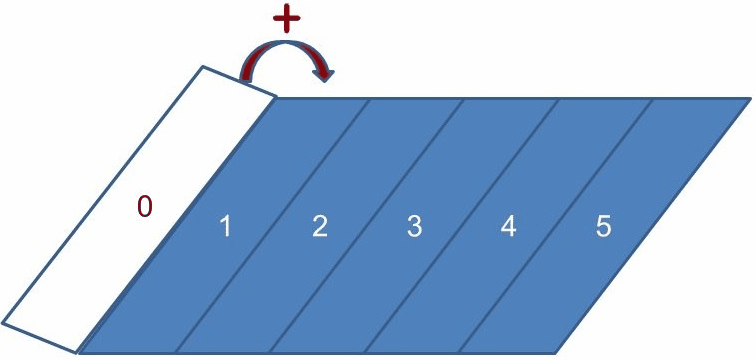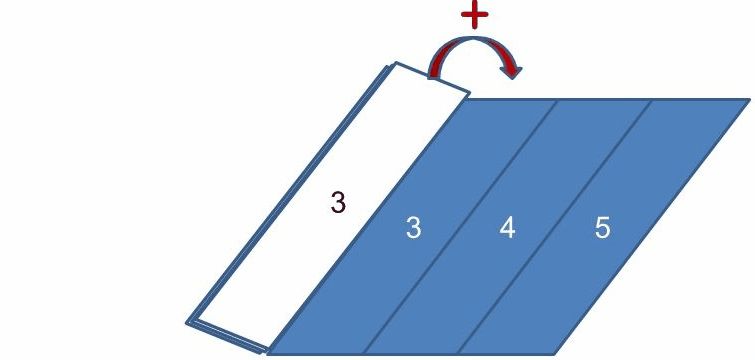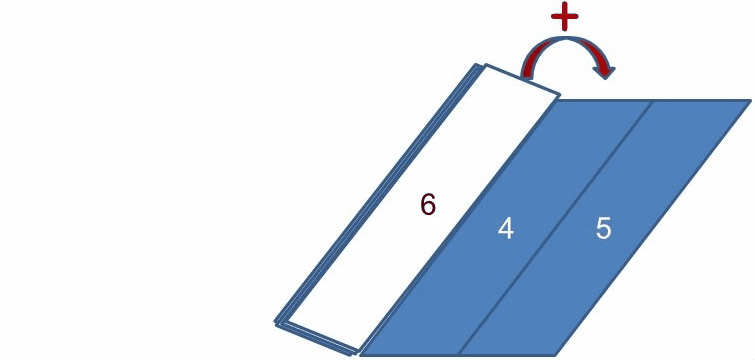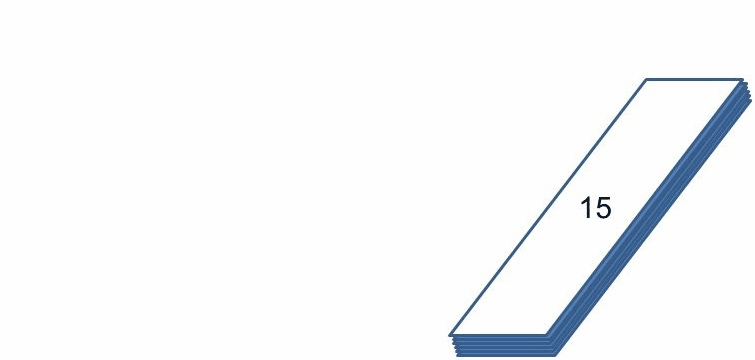
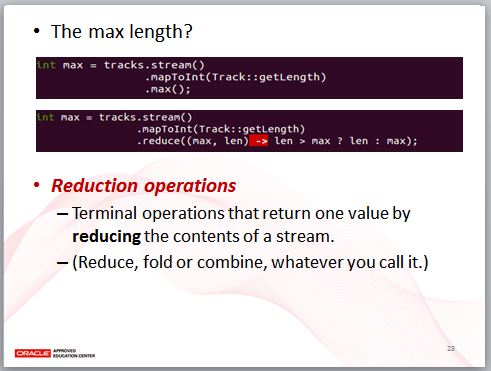
類似地,如果你想要取得歌曲長度超過 60 秒的歌曲中,時間最長的一首,可以在 mapToInt 取得 IntStream 後,呼叫其 max 方法,實際上,你也可以使用 reduce,每次只傳回兩個參數中較大的那個值。
簡單來說,Reduction 操作是終結操作,透過削減 Stream 的內容,逐步求得一個結果,想想看,迴圈操作多半要的也是這種結果,因此,可以使用迴圈的場合,多半也可以使用 Reduction。
就像在別的語言,不想叫 reduce、fold,你也可以叫它 combine,概念都是類似的。

那麼要怎麼透過 reduce 方法,將 Stream 的一組值削減至較短的另一組值或封裝至物件呢?你可以給 reduce 一個初始容器,像是 Set,這個容器會做為 Lambda 的第一個引數,然後你用它來決定要不要將第二個引數,也就是當次迭代的元素加入至容器中,至於第二個 Lambda,與平行處理有關,在平行處理時,可能使用兩個以上的容器來分別處理兩段來源,當兩個容器必須合併時,你透過第二個 Lambda 來決定如何合併。
程式碼有點難懂對吧!?如果你有更複雜的收集需求,那程式碼就會寫得更複雜了,所以,JDK8 建議這類收集的動作,交給 collect 方法來處理。
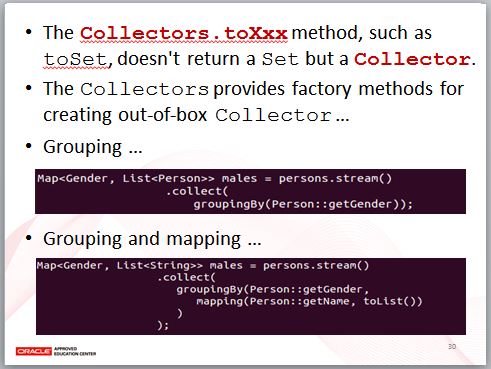
實際上,之前看到的 toList、toSet 等方法,都是 Collectors 的靜態方法,只不過為了可讀性,做了 import static,toSet 方法傳回的不是 Set,而是 Collector,toList 也是。
Collector 實際上是個介面,而 Collectors 上的靜態方法做為一種工廠方法,提供了不少現成的 Collector 實作。
舉例而言,Collectors 上的 groupingBy 也是傳回 Collector 實作,透過適當的程式碼排版,可以提高可讀性,像是收集時依性別做群組,collect 方法依照 groupingBy 的 Collector 實作,將結果收集為一個 Map,男性一組,女性一組。
Collectors 上的靜態方法可以形成另一種流暢 API 風格,例如,如果你想要在分組之後,透過 Person 的 getName 將每個人的姓名收集為 List,那可以透過 mapping 方法。
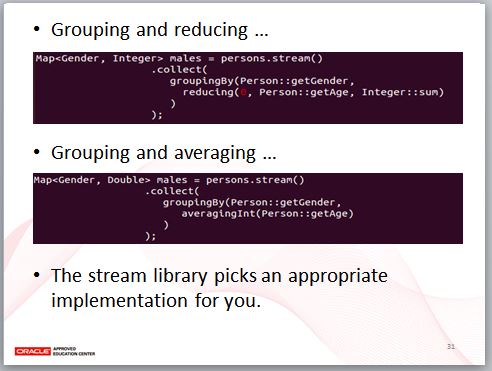
如果想要知道男性與女性個別的年齡總合呢?那就用 reducing 吧!如果要算男性與女性個別的年齡平均呢?那就用 averagingInt。
Collector 的 mapping、reducing、averagingInt 等方法,實際上也是傳回 Collector,這就是為什麼要有 Collector 的原因,因為不同的收集需求被封裝為各個實作了,而各個實作之間,可以透過適當的組合,完成更複雜的收集需求。
Stream API 會為你挑選適當的 Collector 實作,基本上你只要記得 API 命名,然後將程式碼寫得更容易懂一些。

如果,你想要使用特定的 Collection 實作來收集呢?例如,你並不清楚 collect(toSet()) 使用了何種實作,現在希望可以指定使用 TreeSet?
你可以透過 toCollection 方法指定,toCollection 接受一個 Supplier,這邊使用了方法參考語法參考至 TreeSet 的建構式。
實際上,你也可以使用 collect 一個較複雜的版本,指定一個 Supplier 與兩個 BiConsumer,透過方法參考之後,程式碼會比較好懂,分別的作用是,建立收集結果用的容器,指定如何收集結果,以及當有兩個已收集結果的容器要合併時,該如何進行。
實際上,這正是 Collector 介面要實作的三個重要方法,Collector 還有個選擇性的 finisher 方法,如果最後必須對收集結果用的容器做些轉換處理時,可以定義在這個方法中。
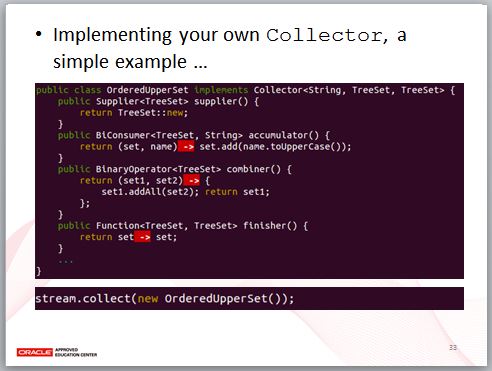
因此,臨時性地複雜收集,可以使用剛剛看到可指定 Lambda 的 collect 方法,如果發現兩個地方有重複的 Lambda,那就可以試著自定義一個 Collector 了。
例如,這邊有個簡單的例子,就是將剛剛的幾個 Lambda,封裝在這個 Collector 實作,這麼一來,就可以直接傳給 collect 方法一個 Collector 就好,當然,也許你可以設計一個靜態方法,讓程式碼變成 collect(toOrderedUpperSet()) 也不錯。

無論是 reduce、collect 或 Collector 的實作,都有一個地方,可以讓你指定兩個容器如何合併,什麼時候會用到兩個容器?嗯!資料可以分而治之,也就是 Divide and conquer 處理之時,既然資料可以分組處理,如果能丟給不同的核心去跑,不是可以增加處理速度嗎?
這就是 JDK8 引入 Lambda 的目的之一,讓平行處理程式容易撰寫!
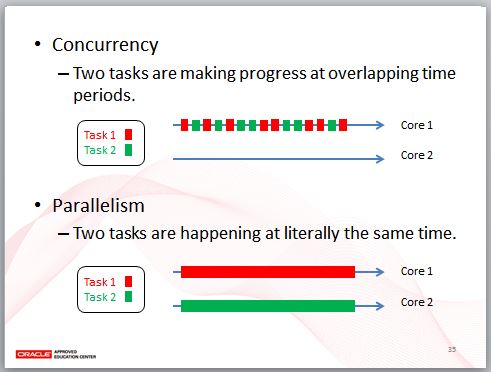
並行與平行不同,並行是指兩個任務在同一個 CPU 核心、同一個時間週期內交替執行,你應該會馬上想到執行緒,以及那些 JSR166 並行 API。
平行是指兩個任務在不同的 CPU 核心上,同時間內進行處理,你可能會想到 JDK7 中的 JSR166y,也就是 Fork-Join 那些東西。
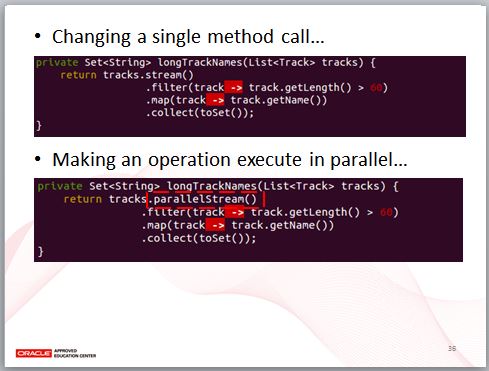
JDK8 引入 Lambda 的目的之一,是讓平行處理程式容易撰寫,舉例來說,這邊的程式碼如果想要具有平行處理的可能性時,只要將 stream 方法改為 parallelStream 就可以了。

注意我剛才的說法,我說的是想要具有平行處理的「可能性」,因為,實際要真正能執行平行處理,還有不少議題需要探討。
舉例來說,如果在 Reduction 時想要能夠有平行處理的可能性,除了 Stream 本身具有平行處理能力之外,Collector 還要具有 CONCURRENT 的特性,而要不就是 Stream 本身是無序的,就是 Collector 得是無序的,也就是具有 UNORDERED 的特性,這個道理很簡單,順序本身就是表示資料上的一種相依性,平行處理可能打散資料分別處理,那就會打亂這種相依性。
內建的 Collector 有些支援平行處理,從命名上可以得知,像是 groupingByConcurrent、toConcurrentMap 傳回的 Collector,就有支援平行處理的特性,因此,從這邊一個沒有平行處理的程式碼,改為有平行處理能力的程式碼,必須將 stream 改為 parallelStream,將 groupingBy 改為 groupingByConcurrent。

方才談到,順序本身就是資料上的一種相依性,因此,平行處理時你的資料不能有順序上的相依,或者是你不能有期待結果順序與來源順序有直接關係。舉例來說,0 到 50 使用 forEach 的結果是有序的,如果使用 parallel,那結果就不一定是 0 到 50 的順序。有些 API 可能保持來源順序,像是 forEachOrdered,不過,這可能會喪失平行處理的優點,畢竟你得等待所有平行處理的片段都完成,才能得到預期的順序。
平行處理時你的資料不能有順序上的相依的原因之一,就是你得考慮合併時的順序可能是隨意的,也就是說,合併時的操作必須是具有結合律的,例如,一組來源資料,可能會隨意地分組相加,而各組相加的結果,也可能以任意的結果進行相加,也就是合併。

平行處理時,資料已經打散分別處理,既然如此,就不能在中途做出干擾資料來源的動作,你已經在個別的每組資料中進行處理了,還得關心個別每組資料與來源的相關性嗎?當然不行,實際上,如果你做了這類的事情,就會拋出 ConcurrentModifiedException。
當然,平行處理的目的,就是為了增加效能,效能這種東西影響的因素很多,資料大小、來源資料結構、CPU 核心數量、每個元素處理時的成本等,再加上你有沒有留意方才提到的一些議題,都會對效能產生不一樣的結果,《Java 8 Lambdas》這本書中,有一些篇幅做了些實驗與探討,你應該去看看!
總而言之,JDK8 引入 Lambda 的目的之一,是讓平行處理程式容易撰寫,可以讓你不用關心 Fork-Join,可以不用擔心子任務的切割,有一些內建的平行處理實作 API 可用,不過,並不表示,你有免費的午餐可以吃,注意到了嗎?先前的範例做重構時,其實就是在切割邏輯泥塊,在這個過程中,儘量讓一塊程式碼一次做一件事,沒有這個過程,你很難使用 Lambda 與 Functional API,也很難進一步再改為平行化版本。
JDK8 的 Lambda 與 Functional API 是個工具,但有個好工具,不代表你有免費午餐可吃,至少,你得學著怎麼使用工具煮飯吧!?

接下來剩下的時間不多,我想來簡單談一下,JDK8 中的 Monad,中文常翻為單子的東西!
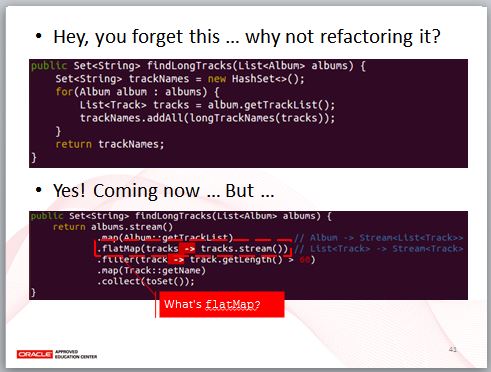
至於為什麼會扯到 Monad,是因為我並沒有忘了,一開始的範例,還有個地方要重構,也就是 findLongTracks,剩下的時間不多,直接讓各位看看使用 Stream API 重構的結果,除了 flatMap 沒看過外,其他的東西你都看過了。
從註解中可以看到,map 的 Lambda 中從 Album 取得了 List<Track>,因此,map 的傳回值是 Stream<List<Track»,flatMap 逐一取得 Stream 中的 List<Track>,然後 Lambda 中取得了 Stream<Track>,這也是 flatMap 的傳回值,因此後面,就是對 Stream<Track> 的操作。
有解釋等於沒有解釋,我相信你一定看不懂,所以,flatMap 到底是什麼?
JDK8 中 flatMap 的概念,要追溯的話,其實是來自 Monad,如果你去 Google Monad,會找到墨西哥捲餅 … 可以吃 … XD
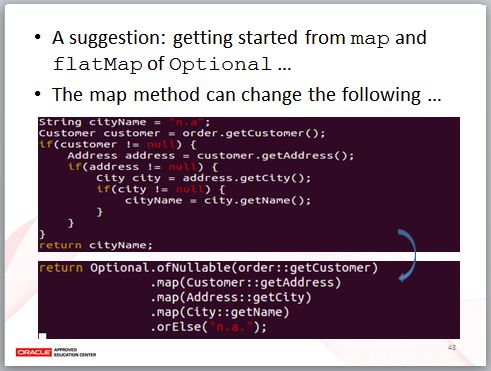
你可以不用理 Monad 這個東西,我建議各位從 Optional 的 map 與 flatMap 開始認識起。
如果這邊的 getXXX 可能傳回 null,為了避免 NullPointerException,你很容易寫出像這樣的巢狀結構,透過 Optional 的 map,你可以將之改變為流暢的風格。

你可以看看 Optional 的原始碼,就會知道 Optional 的 flatMap 封裝了 ifPresent 若為 true,繼續用指定的 Lambda 取得下一個 Optional,否則傳回不包括值的 Optional 之程式碼。
因此,如果 getXXX 傳回的是 Optional,對於如果有值,繼續透過下一層物件這類容易形成巢狀或瀑布式操作的需求,像是這邊的程式碼,getXXX 都是傳回 Optional,每一次都要使用 ifPresent 做判斷的場合,就可以使用 flatMap,形成漂亮的管線操作。
可以將 Optional 想像為一個盒子,flatMap方法會取得盒子中的值給你,並讓你使用 Lambda 表示式指定這個值與下個盒子間的關係,在撰寫與閱讀程式碼時,忽略掉 flatMap 這個名稱,就能比較清楚程式碼的主要意圖。

可以將 Optional 想像是個盒子,就會比較能理解 faltMap 的概念,實際上,這個盒子的類型在 JDK8 中除了 Optional 之外,還有 Stream,以及 CompletableFuture,如果你對這幾個 Monad 盒子有興趣,建議從這邊列出的鏈結開始。

該是總結的時候,嗯?既然是 JDK8 Functional API,我怎麼沒談到 Functional Programming,我在過去幾次的演講中,談過不少 Functional Programming 的東西了,到我的網站上看看就可以了。
其實,當你在重構既有程式碼,讓它們一次做一件事,開始用 filter、map、reduce 繼續重構這些重構後的程式碼、開始試著使用 Optional 取代 null、開始使用平行化工具,像是 parallelStream,開始考慮平行化的各種議題,甚至開始使用 JDK8 中 flatMap 那些源自 Monad 的 API 時,你就已經在做 Functional 風格的程式撰寫了 …
當然,理論基礎有其重要性,不過,JDK8 已經釋出了,我們需要更實務的方式來認識其中的元素,這邊正是 Functional 風格的 Java 實現方式,也是瞭解與導入 Lambda/Functional API 的實務方式。

最後,我留給各位一個小小的練習,《Refactoring》這本書從 1999 年發行至現在了,裏頭的觀念依舊適用,不過,需要一些小小的資訊添加,以跟上這十幾年來一些新的設計觀念。
給各位的練習就是,回去看看第一章,完成其中的範例重構,然後,再使用 JDK8 的 Functional API,繼續重構 Customer 的程式碼。
最後,我以與蘇國鈞大師交流討論時,他講到的一句話,作為這次演講的總結,這句話作為認識 Lambda/Functional API 的起點,非常適合…
「Lambda 就是 重構(重構(程式碼))」!

我會在我的網站 openhome.cc 上,公開今天的投影片與演講內容!

謝謝大家耐心聽完今日的分享!