

無論如何,總是會有需要將 NumPy 陣列中的元素取出的時候,NumPy 的陣列基本上與 Python 內建的 list 具有相同的索引方式,隨便舉幾個例子:
>>> import numpy as np
>>> a = np.array([1, 2, 3, 4, 5])
>>> a[0]
1
>>> a[2:3]
array([3])
>>> a[3:]
array([4, 5])
>>> a[:3]
array([1, 2, 3])
>>> a[:]
array([1, 2, 3, 4, 5])
>>>
就效能而言,a[2:3] 這類指定索引範圍的操作,會比 list 來得快,因此對於這類任務,應該避免使用 for 逐一索引每個元素實現。
對於連續範圍,NumPy 有 View 的概念,基於效能上的考量,傳回的 NumPy 陣列不會逐一複製元素參考,而會是對原陣列的一個觀點,修改新陣列,來源陣列也會被修改,例如:
>>> b = a[3:]
>>> b[0] = 10
>>> a
array([ 1, 2, 3, 10, 5])
>>>
這行為顯然跟 list 不同,必須留意,例如 list 是這樣的:
>>> c = [1, 2, 3]
>>> c = [1, 2, 3, 4, 5]
>>> d = c[3:]
>>> d[0] = 10
>>> c
[1, 2, 3, 4, 5]
>>>
在效能上的考量方面,對於多維陣列,NumPy 有個特別的寫法,例如:
>>> e = np.arange(9).reshape((3, 3))
>>> e1 = e[1][1:3]
>>> e2 = e[1,1:3]
>>> e1
array([4, 5])
>>> e2
array([4, 5])
>>>
就上例來說,e[1][1:3] 與 e[1,1:3] 的結果相同,然而 e[1][1:3] 是取得 e[1] 後,再依索引範圍取得結果陣列;e[1,1:3] 是指 axis 0 索引 1(如下圖藍色)與 axis 1 索引範圍 1 到 3(如下圖綠色)交叉的部份(也就是叉積),可以看看下圖:
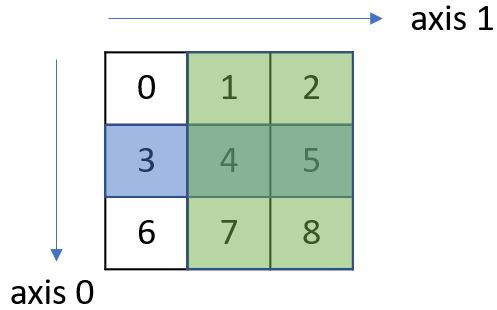
因此 e[1,1:3] 與 e[1][1:3] 正好得到相同結果,然而前者在內部運算上,不另外建立列的 NumPy 陣列,效能會比較好。
這類取法的逗號就是 axis 的分隔,可以推廣至多維陣列,每個逗號間的範圍寫法,與 list 相同,單純指定索引也可以,因此,對於 e[1][2],你也可以寫為 e[1, 2],不過別誤會,[,] 並不是 [][] 的簡略寫法,[,] 這種寫法會得到軸交叉的部份。
例如,底下的程式碼, e3、e4 為什麼結果不一樣呢?
>>> e3 = e[0:2][1]
>>> e4 = e[0:2,1]
>>> e3
array([3, 4, 5])
>>> e4
array([1, 4])
>>>
e3 應該沒問題,e[0:2] 取得一個二維陣列,再取它的索引 1,e4 呢?e[0:2,1] 的寫法,是指 axis 0 索引範圍 0 到 2(如下圖藍色)與 axis 1 索引 1 到 2 交叉的部份(如下圖綠色),看看下圖,就會知道為何結果會是 [1, 4]:
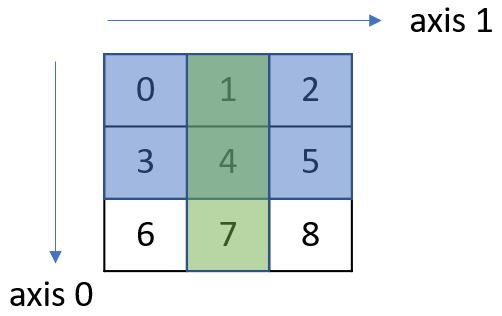
範圍的指定,是可以避免使用 for 逐一索引每個元素,那麼其他索引需求呢?例如,底下的 list 需求該如何用 NumPy 實現?
a = [1, 2, 3, 4, 5]
b = []
for i in range(len(a)):
if i in [0, 1, 4]:
b.append(a[i])
NumPy 的 [] 可以指定索引陣列,例如:
>>> a = np.arange(1, 6)
>>> a[[0, 1, 4]]
array([1, 2, 5])
>>>
指定索引陣列的話,傳回的 NumPy 陣列包含了對應的元素,這樣的索引指定方式稱為 Fancy indexing,多維陣列時,可以有多個索引陣列,使用逗號區隔,表示 axis 的分隔,例如,對於一個二維陣列 a,想取得索引 a[0][0]、a[1][3]、a[4][4],axis 0 上各索引是 [0, 1, 4],axis 1 上各索引是 [0, 3, 4]:
>>> a = np.arange(25).reshape((5, 5))
>>> a[[0, 1, 4], [0, 3, 4]]
array([ 0, 8, 24])
>>>
因為並非連續範圍,指定索引陣列的方式不會建立 View,傳回的 NumPy 陣列會複製參考,修改傳回的陣列,不會對原陣列造成影響:
>>> a = np.arange(25).reshape((5, 5))
>>> b = a[[0, 1, 4], [0, 3, 4]]
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
>>> b
array([ 0, 8, 24])
>>> b[1] = 10
>>> b
array([ 0, 10, 24])
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
>>>
不過你可能會問,如果想要 axis 0 索引 0、1、4 與 axis 1 索引 0、3、4 交叉的部份呢?也就是你想要以下的結果:
[[ 0 3 4]
[ 5 8 9]
[20 23 24]]
這可以透過 ix_ 函式完成,ix 這名稱代表索引的叉積(cross product):
>>> a = np.arange(25).reshape((5, 5))
>>> a[np.ix_([0, 1, 4], [0, 3, 4])]
array([[ 0, 3, 4],
[ 5, 8, 9],
[20, 23, 24]])
>>>
進一步地,索引陣列也可以是布林值組成:
>>> a = np.arange(1, 6)
>>> a[[True, True, False, False, True]]
array([1, 2, 5])
>>>
也就是說,這可以用來實作濾元素之類的任務,對於多維陣列,也是使用逗號區隔,表示 axis 的分隔,各 axis 索引陣列的 and 運算結果為 True 之元素會保留。例如:
>>> a = np.arange(25).reshape((5, 5))
>>> a[(
... [True, True, False, False, True],
... [True, False, True, False, True]
... )]
array([ 0, 7, 24])
>>>
類似地,如果想要從 a 取得這樣的結果:
[
[ 0, 2, 4],
[ 5, 7, 9],
[20, 22, 24]
]
也可以透過 ix_ 函式完成:
>>> a[np.ix_(
... [True, True, False, False, True],
... [True, False, True, False, True]
... )]
array([[ 0, 2, 4],
[ 5, 7, 9],
[20, 22, 24]])
>>>
除了用於取值之外,NumPy 的索引技巧也可用於設值,例如:
>>> a = np.array([1, 2, 3, 4, 5])
>>> a[[1, 2, 3]] = 10
>>> a
array([ 1, 10, 10, 10, 5])
>>> a[[1, 2, 3]] = [100, 200, 300]
>>> a
array([ 1, 100, 200, 300, 5])
>>>
Python 3 以後,有個 ... 語法可以使用,代表 Ellipsis 物件:
>>> ...
Ellipsis
>>> Ellipsis
Ellipsis
>>>
... 代表省略之意,在 NumPy 的實作中,可以使用 Ellipsis 物件來進行切片,代表略過某些維度,例如,若有個陣列代表圖片像素:
>>> img = np.array([
... [[255, 255, 255], [255, 255, 255], [255, 255, 255]],
... [[124, 255, 23], [245, 222, 255], [255, 232, 255]],
... [[135, 255, 23], [245, 123, 255], [255, 23, 35]]
... ])
>>> img.shape
(3, 3, 3)
>>>
如果想取得 img 中第三個維度的第二個元素,雖然可以這麼撰寫:
>> img[:,:,0]
array([[255, 255, 255],
[124, 245, 255],
[135, 245, 255]])
>>>
不過,透過 Ellipsis 物件,可以直接省略先前的維度:
>>> img[...,0]
array([[255, 255, 255],
[124, 245, 255],
[135, 245, 255]])
>>>
有許多維度時,省略前面的維度是常見的應用,不過 Ellipsis 物件在 NumPy 中,可以用在前、中、後,例如:
>>> img[1,...,1]
array([255, 222, 232])
>>>