

如果有一組資料,沒有任何分類標記,有辦法對它們進行分群(Clustering)嗎?呃…通靈比較快!想要分群,總得指定某些條件才能分群,分群演算法有不少,入門時常會先接觸到 K-means 分群,因為它概念上容易理解,實作上也不困難;在機器學習的領域,K-means 演算被歸類在非監督式(unsupervised)學習,意即無需人類標記(標記就是在監督機器,告訴它預測對或不對)也能自動分群。
當然,從需不需要標記這回事來看,確實 K-means 分群是不需要標記,不過它也不是那麼神,並不是沒有任何假設就能自動分群,當你使用 K-means 分群時,其實就表示你同意「資料之間有距離的概念」、「群心勢力範圍內的資料屬於同一群」,也就是實際上,你還是有告訴機器該怎麼做,簡單來說就是,以距離為勢力依據,尋找勢力均衡。
K-means 分群容易理解,就是因為有距離的概念,既然如此,就先用平面上各點的座標來說明好了,若有一堆點散落在平面上:
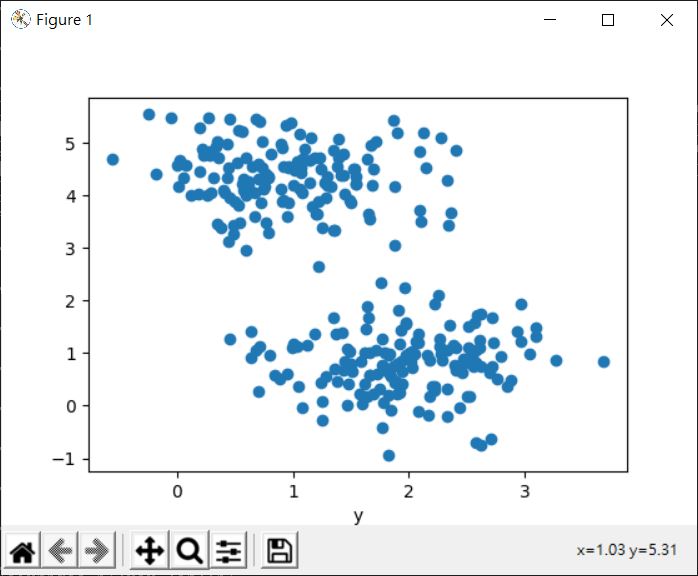
可視化的好處嘛!很簡單就可以用肉眼分辨出點構成了兩群,這其實是因為點與點之間的「距離」構成了視覺上有兩個不同密集度的群,問題在於若要對這些點標記呢?你總不能從圖上逐點找對應的資料,然後標記該資料是哪一群吧!
方才談到 K-means 的另一個假設是「群心勢力範圍內的資料屬於同一群」,那麼該如何尋找群心呢?例如,上例應該要分為兩群,這兩群各自的群心在哪?總不能窮舉出各點間的組合,逐一計算距離,這可是相當龐大的計算啊!
實作 K-means 時可以採取最大期望(Expectation-maximization)演算法,先隨機找兩個位置當群心,接著是期望步驟(Expectation step),看其他點離哪個群心近,就將該點劃為與該群心同一群,最後會得到兩群:
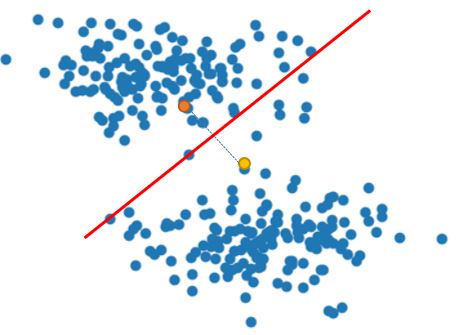
接著是最大化步驟(Maximization step),最大化群心與群中各點的距離,針對兩群的資料,各求其幾何中心,作為新群心,也就是每個座標分量的算術平均值(這也就是為何 K-means 有個 means 字眼的原因了),作為新的群心座標:
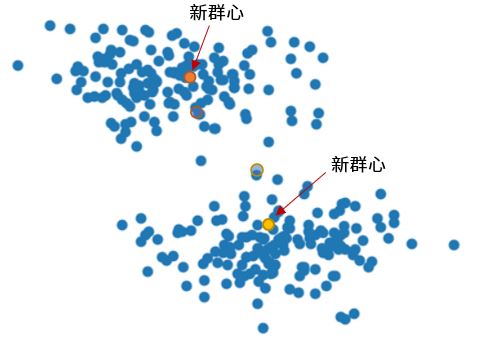
如果舊群心與新群心差距太大(未收斂),重複期望步驟與最大化步驟,也就是同樣地看其他點離哪個群心近,就分為屬於該群心的一群,這又會得到兩群,然後求新群心,看看舊群心與新群心的差距…重複以上步驟,直到舊群心與新群心變動不大(在某個差距內),或者是超過迭代次數。
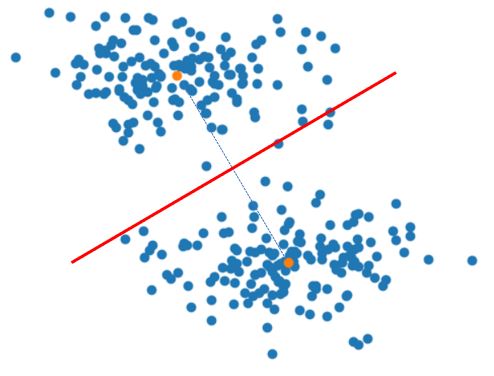
sklearn 提供了 sklearn.cluster.KMeans,可以用來進行 K-means 分群的任務,例如:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, _ = make_blobs(n_samples = 300, centers = 2, cluster_std = 0.6, random_state = 0)
plt.xlabel('x')
plt.ylabel('y')
kmeans = KMeans(n_clusters = 2) # 分兩群
kmeans.fit(X)
centers = kmeans.cluster_centers_ # 群心
y_kmeans = kmeans.predict(X) # 分群
plt.scatter(
X[:,0], X[:,1],
c = y_kmeans, # 指定標記
edgecolor = 'none', # 無邊框
alpha = 0.5 # 不透明度
)
plt.scatter(centers[:, 0], centers[:, 1], marker = 'x')
plt.show()
如〈sklearn.datasets 資料集〉談過的,make 開頭的函式,可以用來建立一些假資料,在這邊借助了 make_blobs 函式,可以用來建立一些常態分配的資料,預設特徵數量為 2(透過 n_features 指定),n_samples 指定要 300 筆資料,centers 指定要有兩個中心,cluster_std 指定了標準差,越小的話點會越集中,random_state 指定隨機種子,這邊為了要固定的資料以便觀察,因而指定了固定值。
make_blobs 其實會對資料標記,不過這邊不使用,而是透過 KMeans 來進行分群,make_blobs 產生的資料會作為座標,來看看分群後的結果:
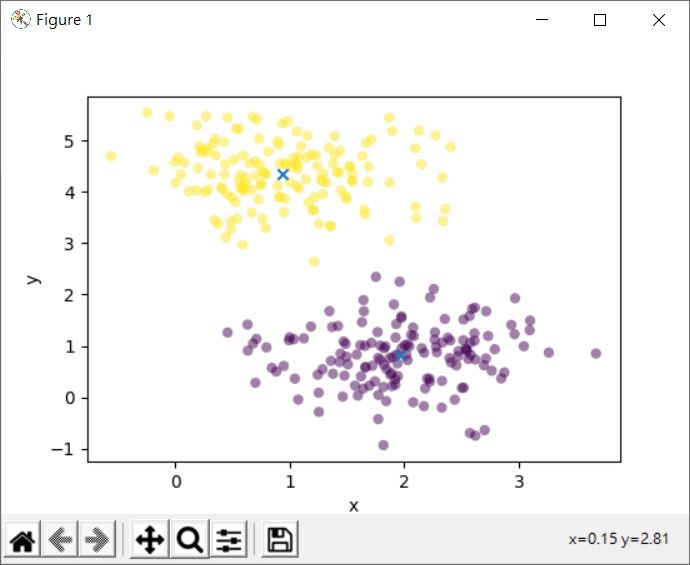
依距離分群,是 K-means 最常的應用之一,特別是資料在距離上可以明顯觀察出一群一群的趨勢時,透過 K-means 就非常的方便。
如果你的資料是座標,很容易瞭解距離遠近是什麼,若是其他資料呢?分數也具有距離的概念,像是各學科分數,例如常聽的,有人文科強、有人理科強,將文科、理科的分數作為資料,可能也會有一群一群的趨勢;另外像是人與人間的年紀差距、學歷差距、年收入差距、子女差距、居住城市發展指標的差距等,都是具有距離遠近的概念。
只不過,有時候手邊的資料,不見得能夠以可視化的方式來判斷可以分為幾群,或者就算能可視化,也看不出群與群之間的界分為何,這時如何能決定該分為幾群呢?
這時 K-means 就是作為一種分析資料的工具了,例如,你手中有一組人們的資料,包含了學歷差距、收入差距、年紀、居住縣市(經緯度、離首都的遠近)等,這些資料會不會有某種群聚性呢?分為三個群合理嗎?還是要四個、五個?如果這些資料能夠分群了,那麼這各群又代表什麼意義呢?政治取向?消費習慣嗎?
這些都是可以透過 K-means 分析、思考的問題,下一篇文件中,會來做一些簡單的討論…