到目前為止,都是用一些身高、腰圍、體重之類的虛擬資料來做範例,總該來點實際點的例子吧!那麼來試著訓練一下圖片分類,只是範例圖片哪裡來呢?
這邊使用 MNIST(Modified National Institute of Standards and Technology database)手寫資料集,其中收集了 250 個人的手寫數字圖片,每張圖片是 28x28 像素的灰階圖,資料集也為每張圖片做了標記,也就是圖片代表哪個數字。
對於使用 Python 的人來說,更方便是被整理並儲存為 Pickle 格式的版本,網路上很容易找到,其中一個來源可以是《Neural Networks and Deep Learning》書附範例中的 mnist.pkl.gz,在下載之後,可以使用 gzip 解壓縮,並透過 pickle 讀取:
import pickle
import gzip
with gzip.open('mnist.pkl.gz') as pkl:
training_data, valid_data, test_data = pickle.load(pkl, encoding = 'bytes')
print(training_data)
在讀入的資料中,可以看到分為訓練(50000 筆)、驗證(10000 筆)與測試(10000 筆),在之前的範例中,我們只區分訓練與驗證資料,其中你可能會想驗證與測試資料又有何不同?
簡單來說,驗證就是對訓練過的模型進行驗證,驗證結果不理想時,可以對模型的一些參數進行調整,簡單來說,驗證資料的在特徵上可能考慮會很多,以便作為模型修正的參考依據。
相對地,測試資料可能是實際你想要預測的資料,來源可能更為隨意,測試資料的預測結果,不會作為模型修正的參考依據。
無論是訓練、驗證或測試資料,都包含了兩個部份,圖片資料與標記,例如上例會顯示:
(array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32), array([5, 0, 4, ..., 8, 4, 8], dtype=int64))
training_data 是個 Tuple,索引 0 包含一組圖片,[0., 0., 0., ..., 0., 0., 0.] 長度是 784,也就是代表一張 28*28 圖片攤平後的灰階值,Tuple 的索引 1 是圖片標記,也就是圖片實際代表的數字。例如,上面的顯示中,第一張圖片是數字 5,透過以下的程式可以驗證:
import pickle
import gzip
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
with gzip.open('mnist.pkl.gz') as pkl:
training_data, valid_data, test_data = pickle.load(pkl, encoding = 'bytes')
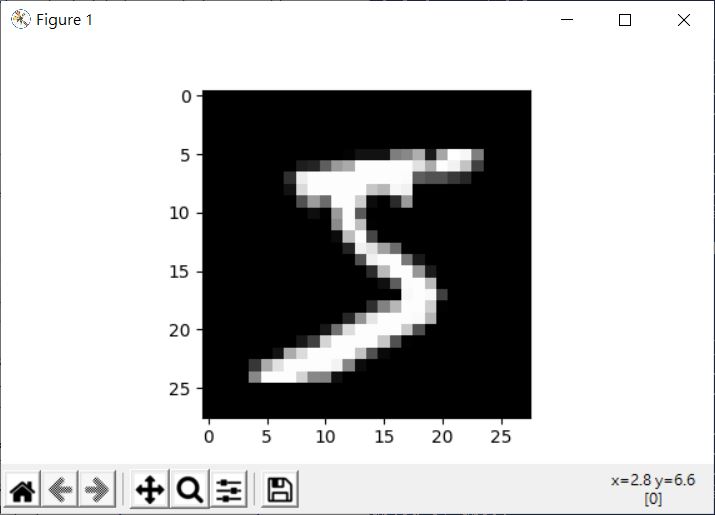
images, label = training_data
plt.imshow(images[0].reshape((28, 28)), cmap = cm.gray)
plt.show()
這會顯示以下的結果:
每個圖片資料的灰階值,會作為多層感知器的輸入,也就是輸入總共會有 784 個,輸出的目標是分為 10 類,也就是 0 到 9 的數字,透過 sklearn 的 MLPClassifier,可以如下撰寫:
import pickle
import gzip
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
with gzip.open('c:\\workspace\\mnist.pkl.gz') as pkl:
training_data, valid_data, test_data = pickle.load(pkl, encoding = 'bytes')
imgs_training_data, lb_training_data = training_data
imgs_valid_data, lb_valid_data = valid_data
img_test_data, lb_test_data = test_data
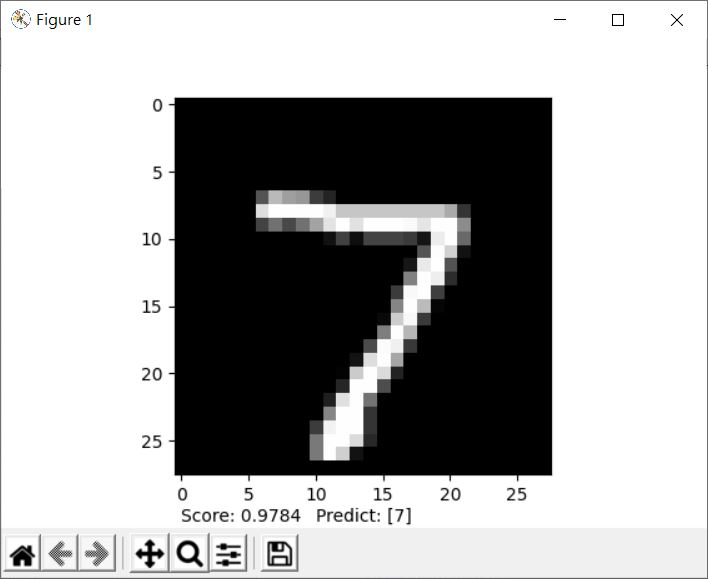
mlp = MLPClassifier() # 用預設值就可以了,可自行查詢文件瞭解預設值
mlp.fit(imgs_training_data, lb_training_data)
# 評估
plt.text(0, 31,
"Score: " + str(mlp.score(imgs_valid_data, lb_valid_data)))
# 實際的測試圖片
plt.imshow(img_test_data[0].reshape((28, 28)), cmap = cm.gray)
# 預測值
plt.text(10, 31,
"Predict: " + str(mlp.predict([img_test_data[0]])))
plt.show()
這會顯示以下的結果: