

接續〈多元線性迴歸(一)〉,來進一步探討 sklearn 的 LinearRegression 進階使用方式。既然 LinearRegression 可以用來求多元線性迴歸,那麼只有一個變數當然也行得通,例如〈多項式迴歸〉中線性的範例,也可以改用 LinearRegression:
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.linear_model import LinearRegression
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
linreg = LinearRegression() # 負責線性迴歸
# 擬合
linreg = linreg.fit(
data_x.reshape((data_x.size, 1)), # 符合 fit 要求的形狀
data_y
)
plt.gca().set_aspect(1)
plt.scatter(data_x, data_y)
x = [0, 50]
y = linreg.predict([[0], [50]]) # 符合 predict 要求的形狀
plt.plot(x, y)
plt.show()
基本上要注意的就是,符合 LinearRegression 的 API 要求,例如必須符合 fit 與 predict 接受的陣列形狀。
雖說 LinearRegression 字面上是線性,不過結合 sklearn.preprocessing.PolynomialFeatures 的話,可以用來求非線性迴歸。
PolynomialFeatures 正如其名,將原本的特徵,基於多項式的階數轉換為另一組特徵,例如,對於一元函式來說,fΘ(x) = Θ0 + Θ1 * x,它的特徵是 (1, x),對於 fΘ(x) = Θ0 + Θ1 * x + Θ2 * x2,它的特徵會是 (1, x, x2)。
PolynomialFeatures 的階數預設為 2,可以借由 degree 指定,來看看實際計算特徵值的例子:
>>> from sklearn.preprocessing import PolynomialFeatures
>>> poly = PolynomialFeatures()
>>> poly.fit_transform([[1], [2], [3]])
array([[1., 1., 1.],
[1., 2., 4.],
[1., 3., 9.]])
>>>
可以看到,當變數只有一個時,若變數值各為 1、2、3,可以透過 fit_transform 計算 (1, x, x2) 的 特徵值,fit_transform 會進行 fit 與 transform,fit 是計算特徵數量,transform 是將給定的變數值轉換為特徵值。
對於某一組特徵值,例如 2 對應的 (1, 2, 4),若 2 對應的值是 7,那麼 7 = Θ0 + Θ1 * 2 + Θ2 * 4 就只是線性關係。
也就是說,當你將資料來源中,橫軸值轉換為特徵值後,就可以用來求特徵值與縱軸值的線性迴歸。例如,將〈多項式迴歸〉中二次的範例,改使用 sklearn 來求:
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
poly = PolynomialFeatures() # 二次多項式
feature = poly.fit_transform(data_x.reshape([data_x.size, 1])) # 特徵值
linreg = LinearRegression() # 線性迴歸
linreg = linreg.fit(feature, data_y) # 擬合
x = np.linspace(0, 50, 50)
y = linreg.predict(
# 記得是特徵值與縱軸的線性關係
poly.fit_transform(x.reshape((x.size, 1)))
)
plt.gca().set_aspect(1)
plt.scatter(data_x, data_y)
plt.plot(x, y)
plt.show()
分別轉換特徵後進行擬合,看來蠻麻煩,明明就是依序操作罷了,你可以使用 make_pipeline 將之串起來:
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
# 管線化
poly_model = make_pipeline(PolynomialFeatures(), LinearRegression())
poly_model.fit(data_x.reshape([data_x.size, 1]), data_y)
x = np.linspace(0, 50, 50)
y = poly_model.predict(x.reshape((x.size, 1)))
plt.gca().set_aspect(1)
plt.scatter(data_x, data_y)
plt.plot(x, y)
plt.show()
從另一個角度來看,上例的原特徵維度是一(也就是 x),被 PolynomialFeatures 轉換後的特徵維度為三(也就是 (1, x, x2)),轉換後的特徵值可以更好地被線性模型 LinearRegression 擬合,這種將特徵提高維度的作法,其實跟後續文件要談到的核方法(Kernel method)有關係。
因為轉換後第一個維度總是 1,故且忽略第一個維度,用 (x, x2) 與 data_y 畫出來:
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
poly = PolynomialFeatures() # 二次多項式
feature = poly.fit_transform(data_x.reshape([data_x.size, 1])) # 特徵值
linreg = LinearRegression() # 線性迴歸
linreg = linreg.fit(feature, data_y) # 擬合
derived_x = poly.fit_transform(data_x.reshape((data_x.size, 1)))
ax = plt.axes(projection='3d')
ax.scatter(data_x, data_y, np.zeros(len(data_x)))
ax.scatter(derived_x[:,1], derived_x[:,2], data_y)
plt.show()
這會呈現以下的結果:
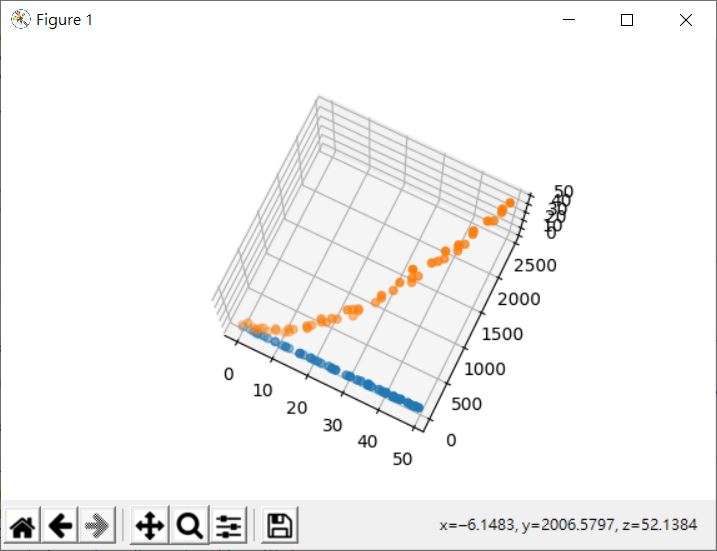
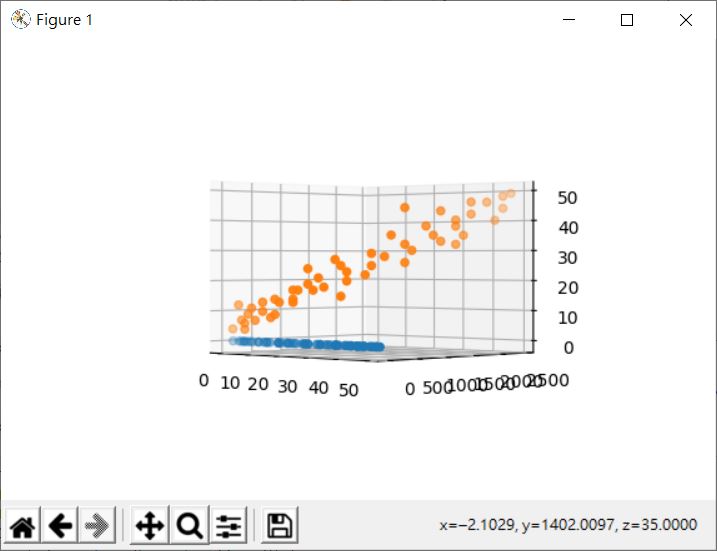
試著旋轉來觀察一下,某個角度下,視覺上可以找到一個線性關係,這意謂著可以尋找一個超平面作為線性迴歸的結果:
PolynomialFeatures 可以套用至多元多次,例如二元(兩個變數 x1、x2)二次的話,特徵值的計算會是 (1, x1, x2, x12, x1 * x2, x22),如果給定一組變數值,也可以透過可以求得 PolynomialFeatures 對應的特徵值:
>>> from sklearn.preprocessing import PolynomialFeatures
>>> poly = PolynomialFeatures()
>>> poly.fit_transform([[1, 2], [3, 4], [5, 6]])
array([[ 1., 1., 2., 1., 2., 4.],
[ 1., 3., 4., 9., 12., 16.],
[ 1., 5., 6., 25., 30., 36.]])
>>>
也就是說,高維度的多元迴歸應該也可以做到,只不過高維度的多元迴歸,事先應該很難觀察出趨勢吧!…XD