

對於高維度(多變數)的資料,會為了想要可視化、抽取特徵、清理資料(去除雜訊、不相關資訊)等理由,想要減少維度(變數),只是該怎麼減少呢?胡亂地去除某些維度(變數)?這當然是行不通的!
例如,在〈sklearn.datasets 資料集〉中 load_digits 載入的手寫數字圖片資料,每張圖片是 8x8,若以每個像素的灰階值作為輸入,維度就是 64,隨便選擇其中一列像素說是降維,其實就損失了 90% 的資訊,損失了這 90%,這圖片代表哪個數字的重要資訊還有可能保留嗎? … XD
也就是說,降低維度的同時,必須能夠保留重要資訊,重要資訊的比例越高越好,因此在這之前,必須要能分析資訊來源的主成分(Principal Component)有哪些,佔了多少比例等資訊,才能夠據以降維,這個過程稱為主成分分析(Principal Component Analysis, PCA)。
分析資訊來源的主成分?這聽來有點抽象!來個具體例子好了,你手上拿著一個東西,用光照後影子投影在布幕上,朋友隔著布幕看著影子,猜測你手上是什麼東西,你手上的東西是三維的,影子是二維的,要怎麼做,朋友才能從影子的資訊得知你拿了什麼?
你必須轉動手上的東西,不同角度時可以投影出不同的輪廓,這時可以說影子帶有你手中物體不同的成分,你必須讓物體投影在布幕上的影子,能夠呈現出足以辨識物體的輪廓,這時可以說影子呈現出你手中物體的主要成分。
物體的投影容易理解,那麼資料該怎麼投影呢?其實當我們談到有一筆資料 (x, y),畫在平面直角座標時,就已經在做投影的動作了,可以將 (x, y) 看成是向量,x 是向量投影在 X 軸的長度,y 是向量投影在 Y 軸的長度。
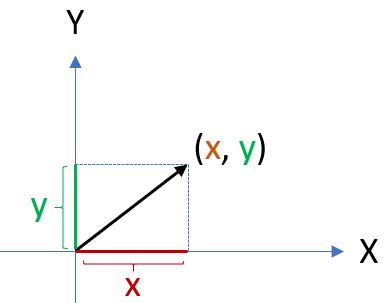
也就是說,x、y 是投影在兩個軸上的兩個成分,如果只旋轉座標軸,會得到不同的值:
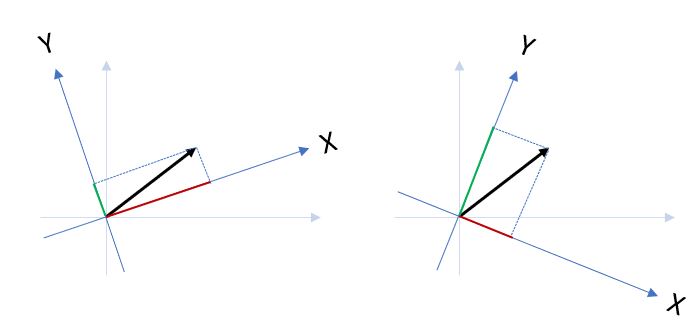
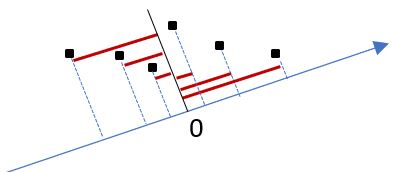
x、y 是投影在兩個軸上的兩個成分,現在單獨來看 x 成分,若有一堆資料,可否找出一個軸,讓這堆資料投影在該軸作為 x 成分,而 x 成分的相異程度最大呢?
類似地,是否也可以找出一個軸,讓這堆資料投影在該軸作為 y 成分,而 y 成分的相異程度最大呢?
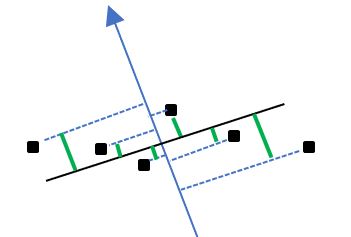
這都是做得到的,若相異程度是透過變異數衡量,現在兩個軸的成分變異數各為 vx 與 vy,而且 vx 大於 vy,這就像是影子投影在布幕時具有較大的範圍,若 vx 比 vy 大上許多,那麼選擇該軸的投影成分,應該會具有較高的代表性。
就方才的例子來說,這兩個軸不見得要是垂直的,如果你有學過線性代數的話,應該會想到,這兩個軸其實就是基底(basis),以這兩個軸來取向量的話,就是 (vx, vy),如果你只看其中之一,就是只從資料投影在其中一個軸的值來觀察資料。
當然,只從資料投影在其中一個軸的值來觀察資料,顯然會損失一些資訊,因此降維時,往往是取相異程度大的主成分,因為若基底為 i、j(都是向量),某資料基於基底的向量為 (vx, vy),用向量來表示該資料就會是 vx * i + vy * j,若 vx 遠大於 vy,大到 j 向量的部份,也就是 vy 的部份可以忽略,這樣降維時才不會損失過多資訊。
透過投影來分析,是試著資料投影在不同維度上,來找出資料中重要的成分,若需要降維,將不重要的成分忽略,這種降維方式,比單純地捨棄某些維度要好得多了。
來以〈多項式迴歸〉隨意散佈的點為例,來分析一下那些點的成分:
import numpy as np
import cv2
from sklearn.decomposition import PCA
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
X = np.dstack((data_x, data_y))[0]
pca = PCA(n_components = 2) # 兩個成分
pca.fit(X) # 計算特徵
print('explained_variance:', pca.explained_variance_) # 變異數
print('mean:', pca.mean_) # 成分平均
print('explained_variance_ratio:', pca.explained_variance_ratio_) # 成分比例
print('components:', pca.components_) # 成分的投影軸向量,又稱特徵向量(eigenvectors)
這會顯示以下的結果:
explained_variance: [385.30558464 8.69252999]
mean: [25.69230769 24.55769231]
explained_variance_ratio: [0.97793764 0.02206236]
components: [[ 0.74448426 0.66764001]
[-0.66764001 0.74448426]]
可以使用成分的投影軸向量,在散佈圖上加上投影軸:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
plt.gca().set_aspect(1)
plt.scatter(data_x, data_y)
X = np.dstack((data_x, data_y))[0]
pca = PCA(n_components = 2) # 兩個成分
pca.fit(X) # 計算特徵
# 繪製兩個軸
# 用變異數的平方當成是向量大小,只是要箭頭長一些
a0 = pca.components_[0] * pca.explained_variance_[0] ** 0.5
# 繪製箭頭
plt.arrow(pca.mean_[0], pca.mean_[1], a0[0], a0[1], width = .25, color = "orange")
a1 = pca.components_[1] * pca.explained_variance_[1] ** 0.5
plt.arrow(pca.mean_[0], pca.mean_[1], a1[0], a1[1], width = .25, color = "green")
plt.show()
執行結果會顯示如下:
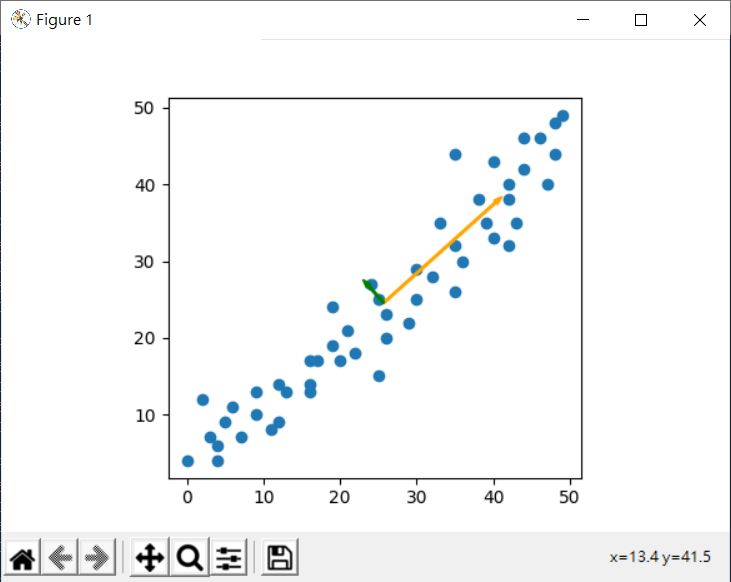
可以將資料分別投影在這兩個軸,顯然地,橘色軸上的投影會有比較大的範圍,這對應了方才 explained_variance_ 看到的成分變異數 [385.30558464 8.69252999] 大小,以及 explained_variance_ratio_ 中看到的比例 [0.97793764 0.02206236]。
來看看另一個可視化的觀點,將投影後的成分各自繪製:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
X = np.dstack((data_x, data_y))[0]
pca = PCA(n_components = 2) # 兩個成分
pca.fit(X) # 計算特徵
X_transformed = pca.transform(X) # 轉換為投影值
plt.scatter(X_transformed[:,0], X_transformed[:,1])
plt.show()
執行結果會顯示如下,可以看到橫軸的成分範圍要大得多了:
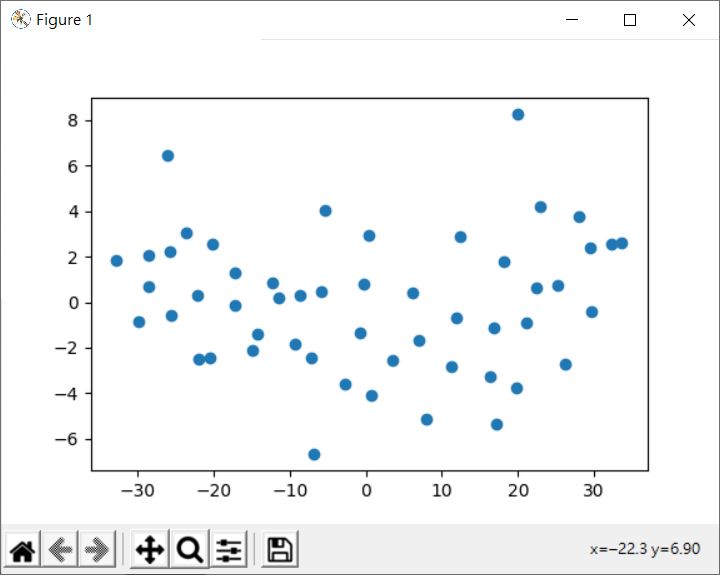
PCA 提供了 inverse_transform 方法,可以將投影值反向轉換回來,就上例來說,因為只是在分析,沒有進行降維,若進行 pca.inverse_transform(X_transformed),會得到原本的資料,這是必然的結果,畢竟這只是使用不同基底來表示一個向量罷了。
sklearn 的 PCA 若 n_components 指定的值,小於來源的維度,會捨棄成分低的部份來進行降維,例如:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
X = np.dstack((data_x, data_y))[0]
pca = PCA(n_components = 1) # 一個成分
pca.fit(X) # 計算特徵
print('explained_variance:', pca.explained_variance_) # 變異數
print('mean:', pca.mean_) # 成分平均
print('explained_variance_ratio:', pca.explained_variance_ratio_) # 成分比例
print('components:', pca.components_) # 成分的投影軸向量
執行後會顯示以下的結果:
explained_variance: [385.30558464]
mean: [25.69230769 24.55769231]
explained_variance_ratio: [0.97793764]
components: [[0.74448426 0.66764001]]
如果這時使用 pca.transform(X),只會得到資料在方才橘色向量上的投影值,這就是降維後的資料,若這時你用於學習或分析,就表示忽略了另一個成分。
到現在為止,是透過二維資料來說明,因為這比較容易理解投影的概念,只不過降為一維後,只是個純量,沒什麼好畫的,當然,或許你可以計算一些最大值、最小值、平均數之類的,結合你想要瞭解的對象,進行可視化。
若是將之透過 inverse_transform 轉回呢?原本散佈的點,會變成投影軸上的點:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
img = cv2.imread('data.jpg', cv2.IMREAD_GRAYSCALE)
idx = np.where(img < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + img.shape[0] # 反轉 y 軸
# 原本的資料
plt.scatter(data_x, data_y)
X = np.dstack((data_x, data_y))[0]
pca = PCA(n_components = 1) # 一個成分
pca.fit(X) # 計算特徵
X_transformed = pca.transform(X) # 轉換為投影值
X_inverse_transformed = pca.inverse_transform(X_transformed) # 逆轉換
# 降維後的資料
plt.scatter(X_inverse_transformed[:,0], X_inverse_transformed[:,1])
plt.show()
這會顯示以下的結果:
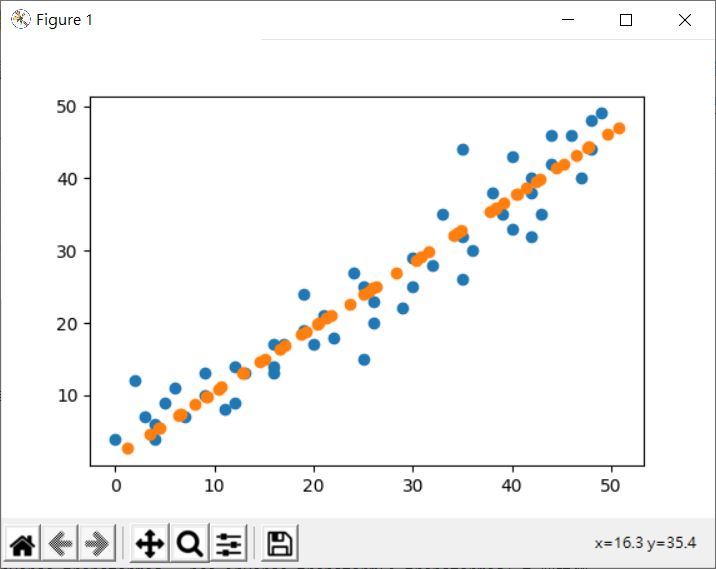
因為是將一維轉回二維,轉回二維前,因為沒有另一個維度的資訊,該維度會被設為 0,逆轉換後的結果,就是原本一堆散落的點,變成直線上的點,感覺像是做了線性迴歸?主成分分析間的轉換,本來就是一種線性轉換,就二維投影在一維來說,就是投影在直線軸上,看來確實就像是在找出線性關係。
某些程度上,這也是主成分分析之目的,就這邊的例子來說,觀察原本的資料,似乎是延著某個線性在變化著,也就是說,有時候我們觀察原本的資料,會發現資料的變化似乎循著某個或某些維度,透過主成分分析進行降維,就是想取得這個或這些維度。
將此概念延伸,若是三維的話,降維就是投影在平面,四維投影在三維就是立體空間,事實上,更高維度的降維,才是主成分分析最主要的應用場合(而不是二維降為一維、三維降為二維這種簡單的情境),透過主成分分析來找出彼此間相關性高的主要成分。
從另一個角度來看,主成分分析藉由投影,來理解資料在不同維度上的樣貌,是分析、理解或清理資料的一種方法,不過要注意的是,主成分分析的重點在於分析,而不是降維,降維有時只是分析、理解資料時的一個過程,而不是最終之目的,最後不見得是使用降維後的資料,而仍是使用原資料來進行運算。
例如,圖片具有很高的維度,以 8x8 個像素的灰階圖來說,維度為 64,就可以試著透過主成分分析來找出圖片之間的相關性,然而最終可能還是會用原圖片資料來進行運算,這部份就留待下一篇文件再來聊…