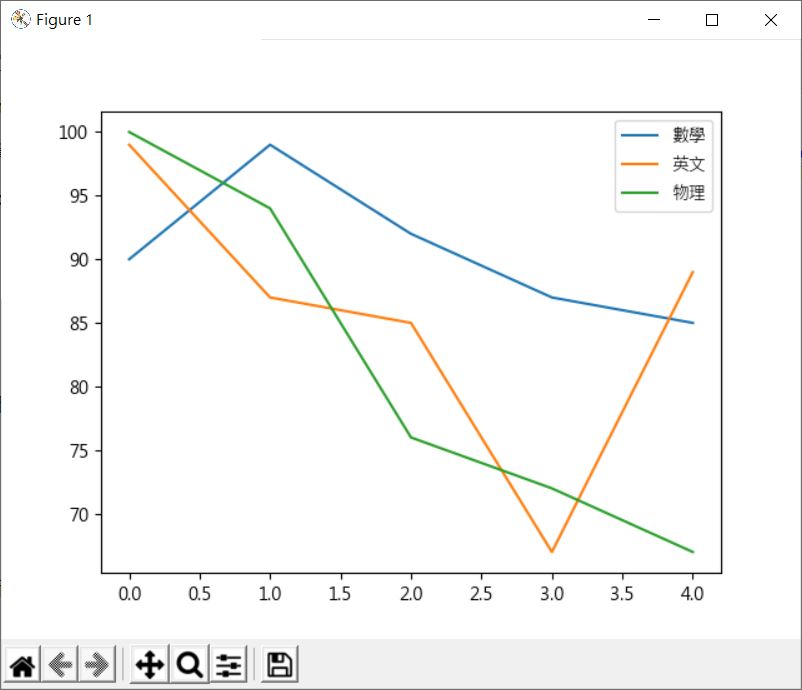
在資料的輸入方面,Pandas 提供了豐富的 API,可以讀取各種格式的檔案,像是常見的 CSV、Excel、JSON 等,以讀取 CSV 為例,若 score.csv 有以下內容:
數學,英文,物理
90,99,100
99,87,94
92,85,76
87,67,72
85,89,67
讀入的資料自動封裝為 DataFrame 傳回,因此底下的程式就可以讀取並顯示圖表:
import matplotlib.pyplot as plt
import pandas as pd
pd.read_csv('score.csv').plot()
plt.show()
顯示的結果如下:
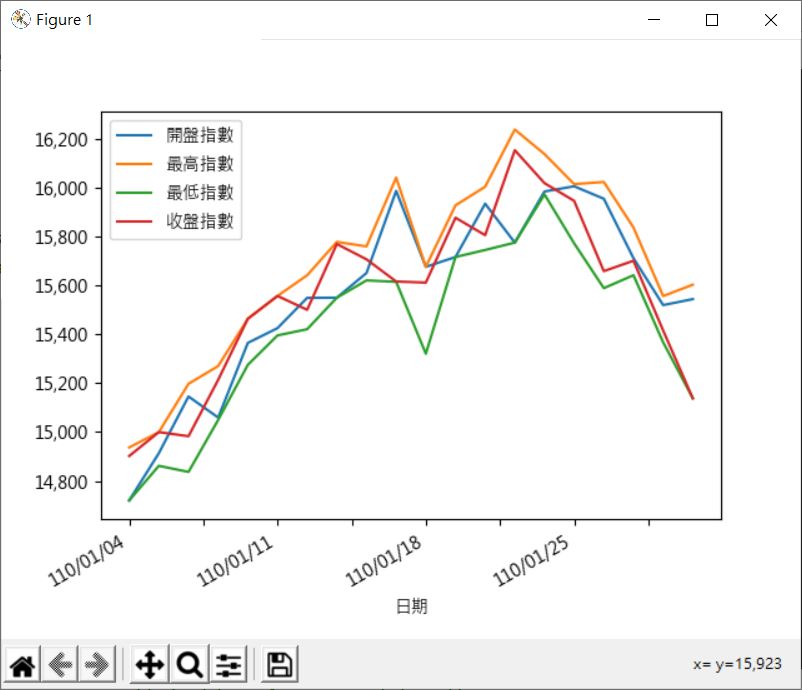
圖表中的 x 軸預設使用數字索引是個問題,另一方面,來源資料實際上往往需要進一步的處理,以〈NumPy 載入文字檔〉中發行量加權股價指數歷史資料的 CSV 檔案為例,若使用以下的程式讀入:
import pandas as pd
hist = pd.read_csv('MI_5MINS_HIST.csv', encoding = 'Big5')
print(hist)
會顯示以下的內容:
110年01月 發行量加權股價指數歷史資料
日期 開盤指數 最高指數 最低指數 收盤指數 NaN
110/01/04 14,720.25 14,937.13 14,720.25 14,902.03 NaN
110/01/05 14,913.64 15,000.03 14,861.99 15,000.03 NaN
110/01/06 15,145.85 15,197.68 14,837.00 14,983.13 NaN
110/01/07 15,059.52 15,270.40 15,049.86 15,214.00 NaN
...
第一列的資料是不需要的,而且最後一行是 NaN?這是因為來源 CSV 檔案每一列最後都有個逗號,等於多一個欄位,而該欄位沒有資料,這時 Pandas 會自行補上 NaN。
第一列的資料可以指定 skiprows 來略過,至於不需要的最後一行,可以透過 iloc 來去除:
hist = pd.read_csv('MI_5MINS_HIST.csv',
encoding = 'Big5',
skiprows = 1,
index_col = '日期').iloc[:,:-1]
上例中也透過 index_col 指定了日期作為索引行,行的選擇也可以透過 usecols,例如:
hist = pd.read_csv('MI_5MINS_HIST.csv',
encoding = 'Big5',
skiprows = 1,
usecols = ['日期', '開盤指數', '最高指數', '最低指數', '收盤指數'],
index_col = '日期')
讀入的資料是以日期作為索引,然而指數部份需要數值才能繪圖,因而需要進一步處理,若是 DataFrame,可以透過 applymap,指定對行元素全部套用的函式,例如:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import locale
locale.setlocale(locale.LC_NUMERIC, 'zh_TW.UTF-8')
atof = np.frompyfunc(locale.atof, 1, 1)
hist = pd.read_csv('MI_5MINS_HIST.csv',
encoding = 'Big5',
skiprows = 1,
index_col = '日期').iloc[:,:-1]
# 對元素套用函式
ax = hist.applymap(atof).plot()
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
plt.gcf().autofmt_xdate()
plt.show()
對於 Series 的話,可以使用 map,另外還有個 apply,可以針對 Series 或 DataFrame,指定 axis 來套用函式。
以上範例可以顯示的圖形如下:
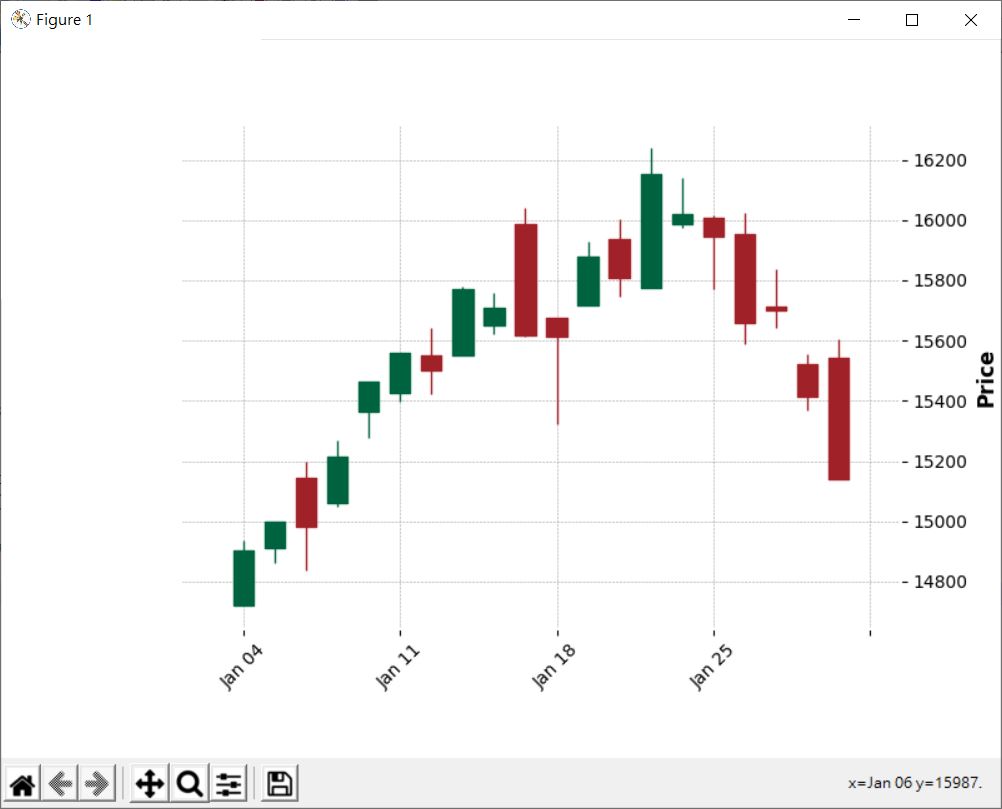
看到上圖,你可能會想說,能不能畫個 K 線圖(candlestick chart)吧!這需要 mplfinance,必須額外安裝,例如:
pip install --upgrade mplfinance
mplfinance 的前身是已經被廢棄的 mpl-finance,透過以上指令,如果已經存在 mpl-finance,就會昇級為 mplfinance,直接來看怎麼畫 K 線圖:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import locale
import mplfinance as mpf
from datetime import datetime
def date_parser(minguo):
y, m, d = minguo.split('/')
year = int(y) + 1911 # 轉西元年
return datetime.strptime(f'{year}/{m}/{d}', '%Y/%m/%d')
locale.setlocale(locale.LC_NUMERIC, 'zh_TW.UTF-8')
atof = np.frompyfunc(locale.atof, 1, 1)
hist = pd.read_csv('MI_5MINS_HIST.csv',
encoding = 'Big5',
skiprows = 1,
index_col = 0,
date_parser = date_parser).iloc[:,:-1].applymap(atof)
hist.to_csv('xxx.csv') # 另存 CSV
mpf.plot(hist, type='candle', style='charles',
columns = ['開盤指數', '最高指數', '最低指數', '收盤指數', '成交量'])
plt.show()
mplfinance 會使用日期索引,而且必須是 DatetimeIndex 實例,這可以透過 read_csv 的 index_col 指定欄位,然而〈NumPy 載入文字檔〉中發行量加權股價指數歷史資料的 CSV 檔案中,日期使用的是民國年,在剖析日期時必須使用西元年,因此這邊自行指定了 date_parser。
mplfinance 預設必須使用的欄位順序是 'open'、'high'、'low'、'close' 以及一個選擇性的 'volume',你可以直接更改 DataFrame 的 columns,或者是呼叫 mplfinance 的 plot 時透過 columns 指定自訂的欄位名稱,雖然 'volume' 是選擇性的,不過透過 columns 自訂欄位名稱時,必須都列出來。
如果你想要將處理過後的資料存下來,DataFrame 提供了 to_csv、to_excel、to_json 等方法。
以上的範例畫出來的圖如下: