

如果條件已知,想要進行對象的分類並不是難事,例如,對於基本的二元分類來說,一個數字大於 0、小於 0、一張圖片的高度是否大於寬度,這些要寫程式來判斷是很簡單的一件事。
然而有時候,有些分類的條件並不是那麼明確,例如,判斷圖片中的動物是貓或狗、男或女、胖或瘦等;對人類來說,看到圖片或許很簡單就可以分辨,然而辨識的條件是怎麼一回事,人們往往都不是那麼清楚,畢竟這是從過去經驗中不斷學習而來的,既然不是很清楚辨識的條件,就無法直接透過程式來定義條件以實現對應的分類。
不過,進一步問人們是怎麼辨識照片是貓或狗的話,其實多多少少都還是可以回答一些基本的觀點要點,若能先請人們標記照片是貓或狗,並整理一下他們的觀察要點,也就是借助人們的大量觀察,事先將一組照片分類好,若觀察要點抓取適當,可以建立起適當的模型,用來對新照片進行貓或狗的分類。
當然,一下子就想學會分類貓狗是太難了些,就假設現在給 50 張照片,讓人來標記照片中的人是不是過胖好了,而每張照片中的人,其實都有對應的一筆資料,記錄該人的身高與腰圍,結果最後得到的記錄是:
171,110,-1
157,90,-1
164,115,-1
182,75,1
160,103,-1
...
這些資料是存為 CSV,第一個欄位是身高,第二個欄位是腰圍,第三個欄位是標記,若為 1,表示沒有過胖,-1 表示過胖,標記不一定要是 1 與 -1,也可以是 1 或 0 之類可區分兩類的標記就可以了。
若 CSV 存為 height_waist.csv,現在透過 Matplotlib:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
data = np.loadtxt('height_waist.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
normal_weight = label == 1
overweight = label == -1
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = 'o')
plt.scatter(data[overweight, 0], data[overweight, 1], marker = 'x')
plt.show()
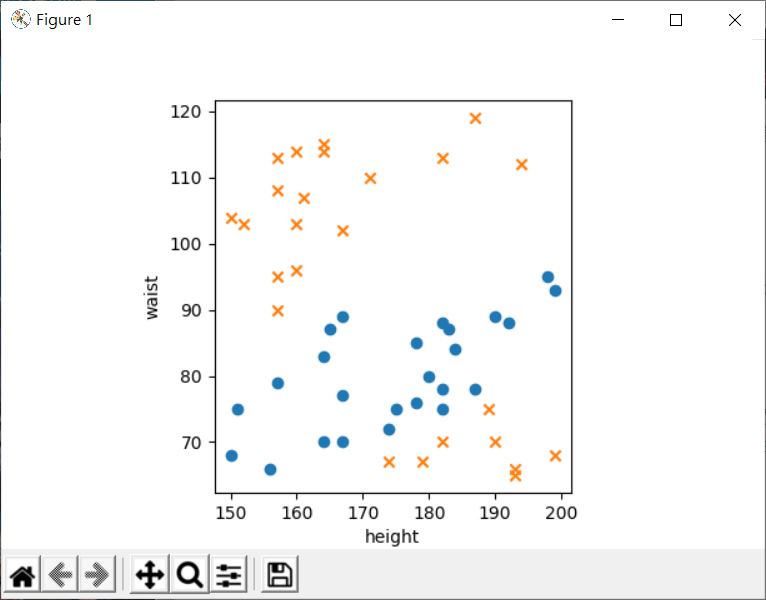
結果發現畫出來的結果,可觀察出標記處明顯分為兩群:
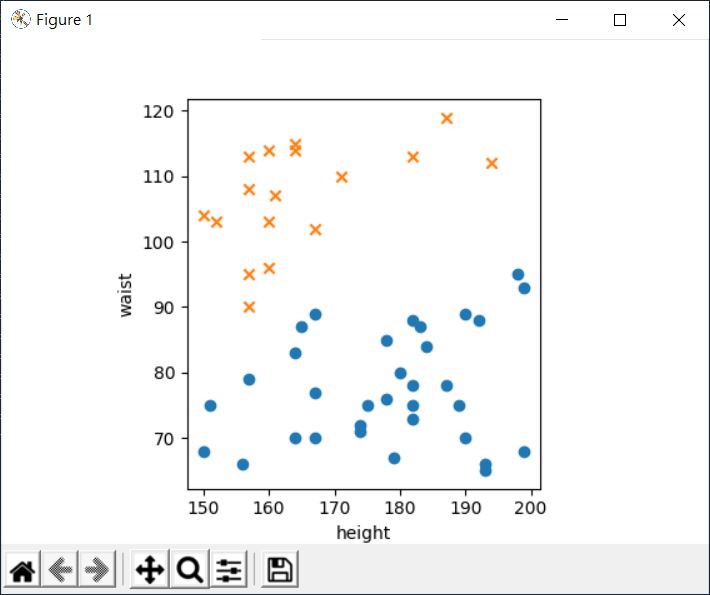
如果可以找出一條直線,這條稱為決策邊界(decision boundary)的線,將這兩群隔開,那麼日後就可以用該直線來判斷,某組身體與腰圍是不是過胖了,因為就上圖而言,過胖的數據,會是在直線左半邊:
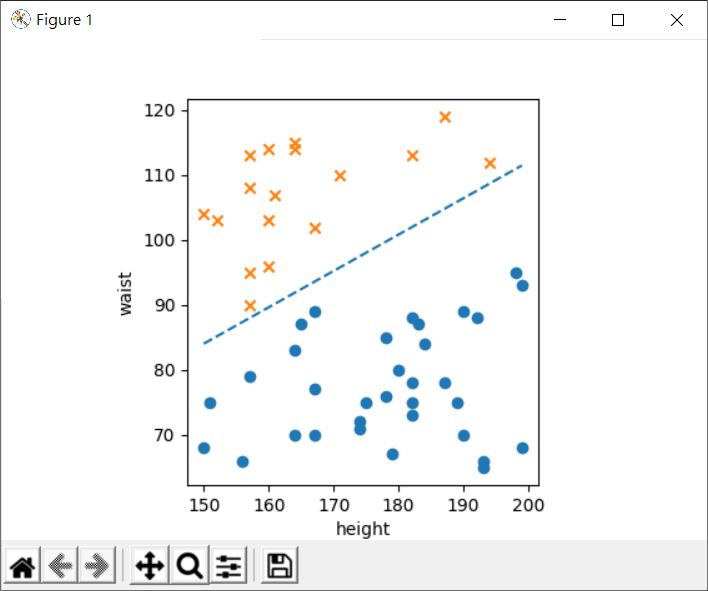
不過,直線左半邊或右半邊是籠統的說法,從向量來看的話會比較清楚,也就是直線法向量指向的那邊是過胖數據。
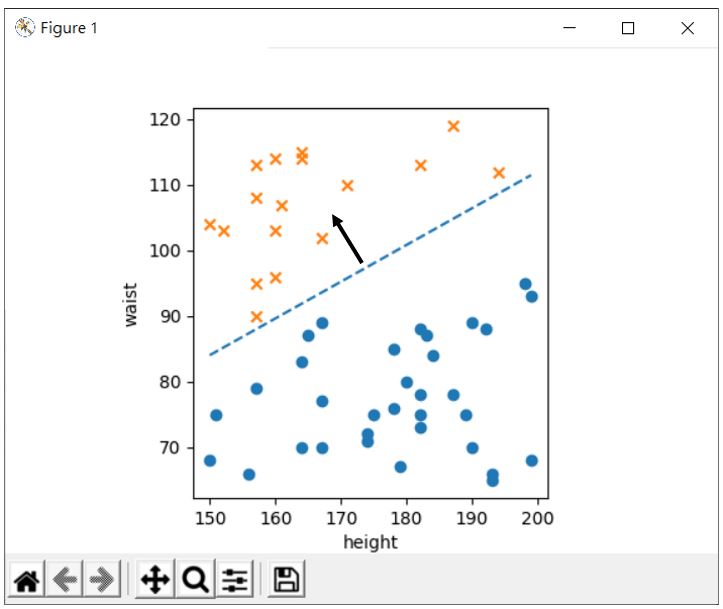
如果這是條通過原點的直線,直線上的每個點與原點構成的向量,與法向量的內積會是 0,也就是若法向量是 [w0, w1],點是 [x, y],那麼 w0 * x + w1 * y 會是 0。
當然,通常不會只有像這邊身高與腰圍兩個變數,因此可以寫為更一般化的 w0 * x1 + w1 * x2,x1、x2 代表各個變數(像是身高與腰圍),這邊採用兩個變數,是因為透過向量,較容易理解分類的最基本原理。
在更多變數的情況下,向量不會只有兩個維度,如果向量 W 是 [w0, w1, w2, …],向量 X 是 [x0, x1, x2, …],那麼內積 W . X = w0 * x0 + w1 * x1 + w2 * x2 + w3 * x3 + ...,這時可以用畫圖的方式來表示一下:
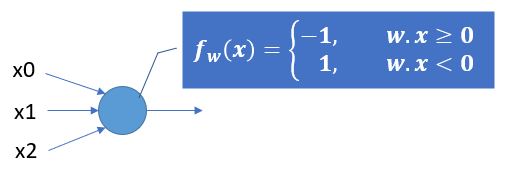
這樣的模型稱為感知器(Perceptron),W 稱為權重向量,fw(x) 稱為識別函數,1、-1 是標記,識別函式的輸出是否符合對應資料的標記,會用來決定如何更新權重向量 w。
若只有兩個變數,更新權重向量的過程,就會像是旋轉直線的法向量(也就是權重向量),法向量旋轉代表著直線旋轉,更新過程會一直持續到直線可以將資料劃分為兩群為止。
回過頭來看看方才只有身高與腰圍的例子,有沒有程式庫將旋轉直線的法向量過程實現了呢?可以透過 sklearn.linear_model 的 Perceptron,例如:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
data = np.loadtxt('height_waist.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
normal_weight = label == 1
overweight = label == -1
# 建立感知器
p = Perceptron()
# 提供資料與標記
p.fit(height_waist, label)
# 取得權重向量
coef = p.coef_[0]
# 截距
intercept = p.intercept_
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = 'o')
plt.scatter(data[overweight, 0], data[overweight, 1], marker = 'x')
height = height_waist[:,0]
h = np.arange(np.min(height), np.max(height))
w = -(coef[0] * h + intercept) / coef[1]
plt.plot(h, w, linestyle='dashed')
plt.show()
Perceptron 提供了 predict 方法,可以指定變數來分類。例如,底下給了兩組資料,前者是屬於不算胖,後者是算胖的分類:
# 顯示 [1. -1.]
print(p.predict([[175, 60], [165, 100]]))
當然,就這個例子來說,要能夠用直線畫分,代表這些資料是線性可分的,若不是線性可分,例如下圖,身高腰圍適中的是藍色,太胖或太瘦是橘色的話,顯然是沒辦法用一條直線來劃分:
也就是說,只使用一個感知器,是沒辦法對這種狀況進行分類的,然而可以使用多個感知器,分層來解決,這在之後還會討論…