

如果想產生一條隨機的曲線,最基本的想法是隨機函式,在每個 x 處產生一個隨機的 y 值吧!例如,Python 本身的 random 模組,提供了一些生成隨機值的函式:
from random import randint
import matplotlib.pyplot as plt
width = 500
xs = [i for i in range(0, width, 5)]
ys = [randint(0, 255) for i in range(0, width, 5)]
plt.title('noise')
plt.xlabel('x')
plt.ylabel('y')
plt.gca().set_aspect(1)
plt.plot(xs, ys)
plt.show()
不過,這樣的線連接起來後,比較像個折線,不連續而且無規律:
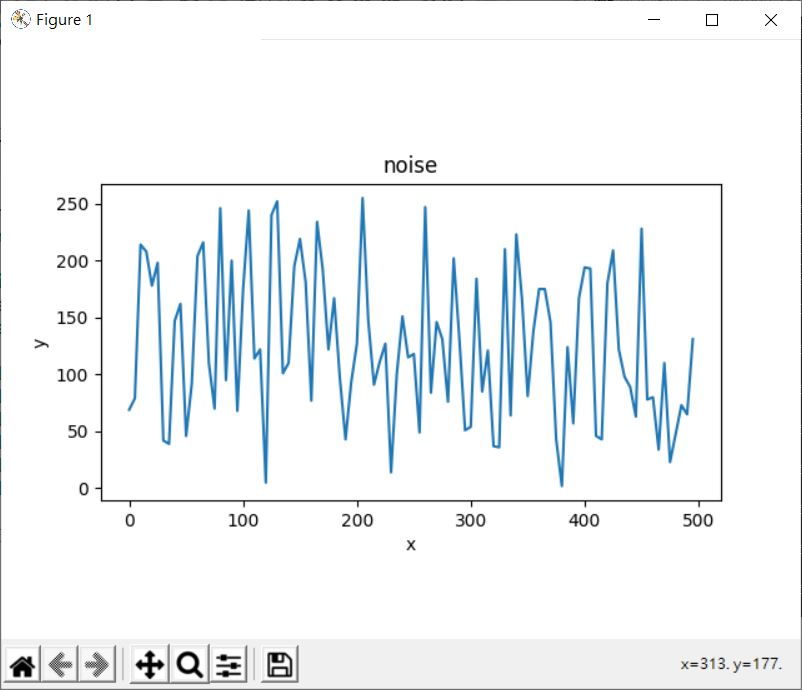
random 模組的函式,產生的值不會是連續的,想想看,自然界有許多看似隨機,然而卻又連續的現象,例如岳崚起伏,看似不規則,然而高低之間又有一定的連續性,如果想要在程式中模擬這種隨機又連續的現象,可以考慮 Perlin 雜訊,完整的原理說明可在〈Simplex noise demystified〉看到。
來介紹一維 Perlin 雜訊的基本原理,你可以在每個整數 x 點產生一個隨機值,然而這個隨機值並不作為 y 值,而是作為穿越該點的一條線之斜率,而該線是曲線在該點的切線:
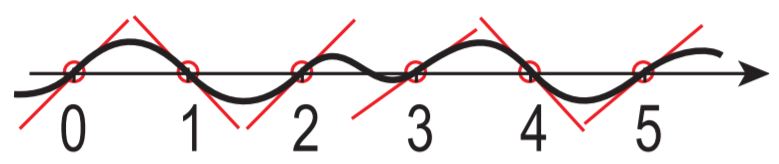
Perlin 雜訊取得斜率的方式是,對於一個非整數的 x 值,如下取得 s1 與 s2:
xi = floor(x)
s1 = x - xi
s2 = s1 - 1
s1 會是 0 到 1,s2 會是 -1 到 0,可以用來決定斜率,如果單純只有 xi、 x、xi + 1 三個點,可以決定出斜率:
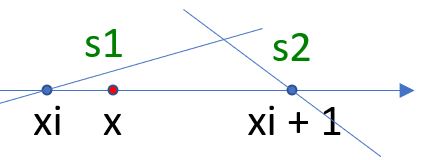
不過,每個點的斜率會是隨機地有正有負,為此,可以寫個 grad1 函式,隨機傳入 0 或 1,來決定要不要改變斜率正負,不過,Perlin 最初是使用 256 個隨機整數來計算,並稱其最後取得的斜率為梯度(gradient),這是因為 Perlin 雜訊的原理可以擴展至更高維度,也就不限於斜率的觀念,在更高維度時,會將各維度(變數)偏微分後結合為向量,該向量稱為梯度,為此來寫個 grad1:
def grad1(n, s):
return s if n % 2 == 0 else -s
為了得到標準化為 -1 到 1 的雜訊值,由於 s1、s2 間的過渡變化會是 -1 到 1,就來寫個 lerp:
def lerp(s1, s2, t):
return s1 + t * (s2 - s1)
t 會是 0 到 1 的值,只不過 t 不能是線性的,因為會造成曲線的不連續,Perlin 提出過兩種公式:
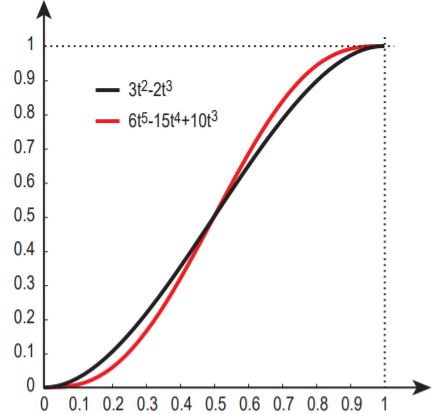
黑色線是 Perlin 最初提出的公式,後來改為紅色線的公式,以得到更好的連續性,為此來寫個 blending:
def blending(t):
return 6 * (t ** 5) - 15 * (t ** 4) + 10 * (t ** 3)
將以上程式碼整理一下,可以如下撰寫 perlin1 函式:
from math import floor
from random import randint
import matplotlib.pyplot as plt
def blending(t):
return 6 * (t ** 5) - 15 * (t ** 4) + 10 * (t ** 3)
def lerp(s1, s2, t):
return s1 + t * (s2 - s1)
def grad1(n, s):
return s if n % 2 == 0 else -s
rand_table = [randint(0, 255) for i in range(256)]
def perlin1(x):
xi = floor(x)
s = x - xi
a = rand_table[xi % 256]
b = rand_table[(xi + 1) % 256]
return lerp(grad1(a, s), grad1(b, s - 1), blending(s))
width = 500
xs = [i for i in range(width)]
ys = [perlin1(x / 100) * 250 for x in xs]
plt.title('Perlin noise')
plt.xlabel('x')
plt.ylabel('y')
plt.gca().set_aspect(1)
plt.plot(xs, ys)
plt.show()
記得在取 Perlin 雜訊時,指定的值若是整數,得到的雜訊值會是 0,因此上例中,將每個 x 除以 100,這樣就會有小數的數值,取得的雜訊值記得會是 -1 到 1 的結果,再看你要怎麼利用雜訊值了,上例中只是單純乘上 250,結果會畫出下圖:
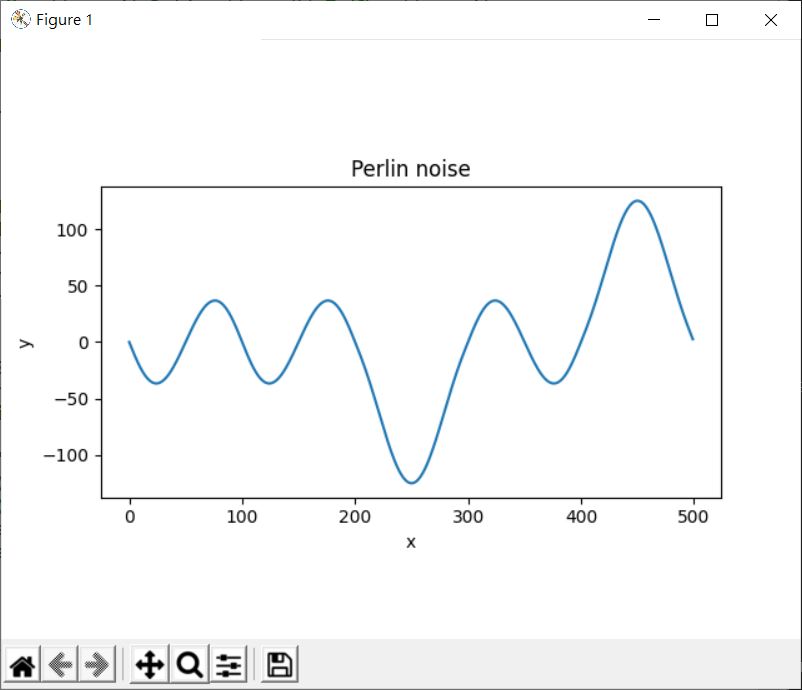
好吧!這跟 NumPy 有關係嗎?如果想要用 NumPy 來做,比較簡單的方式,就是直接向量化 perlin1 函式,並且 rand_table 透過 np.random.randint(255, size = 256),只不過這樣的話,就算 perlin1 向量化了,最後還是使用單一索引來存取 rand_table。
為了讓事情有趣一些,以下的範例將 blending、lerp、grad1 函式向量化,而 perlin1 採用 NumPy 風格,一次處理一個任務的方式來實作:
import numpy as np
from math import floor
from random import randint
import matplotlib.pyplot as plt
def blending(t):
return 6 * (t ** 5) - 15 * (t ** 4) + 10 * (t ** 3)
blending = np.frompyfunc(blending, 1, 1)
def lerp(s1, s2, t):
return s1 + t * (s2 - s1)
lerp = np.frompyfunc(lerp, 3, 1)
def grad1(n, s):
return s if n % 2 == 0 else -s
grad1 = np.frompyfunc(grad1, 2, 1)
rand_table = np.random.randint(255, size = 256)
def perlin1(x):
xi = np.floor(x) # 全部的 xi
s = x - xi # 全部的斜率
a = rand_table[(xi % 256).astype(np.int)] # 全部的隨機 a
b = rand_table[((xi + 1) % 256).astype(np.int)] # 全部的隨機 b
return lerp(grad1(a, s), grad1(b, s - 1), blending(s)) # 全部的雜訊
width = 500
x = np.arange(width)
y = perlin1(x / 100) * 250
plt.title('Perlin noise')
plt.xlabel('x')
plt.ylabel('y')
plt.gca().set_aspect(1)
plt.plot(x, y)
plt.show()
運行的結果也是隨機曲線圖,你可以自行試著從前一個單純 Python 程式碼的實作,練習改為全部 NumPy 風格,這會用上先前文件談過的許多觀念,試試看吧!