

在〈NumPy 與 Matplotlib〉看過 np.sin 函式,它可以接受 NumPy 陣列,對全部的元素套用運算,NumPy 提供的這類函式,稱為 Universal 函式,NumPy 提供了許多內建的 Universal 函式,為 numpy.ufunc 的實例,在底層是以 C 實現,具有高運算效能。
然而有時候,需要的運算在 NumPy 沒有提供怎麼辦?NumPy 提供了 frompyfunc,可以將一般的 Python 函式包裹為 numpy.ufunc 實例,這稱為向量化(vectorization)。
為了實際體會一下使用的時機,來看看一個需求,我在 Twitter 上看到了一個 tweet,簡單地使用兩個迴圈,就可以畫出謝爾賓斯基三角形,它使用的虛擬碼是:
for i in 0..256 {
for j in 0..256 {
if i & j == 0 { White } else { Black }
}
}
這也可以在文字模式下實作,若文字模式的前景顏色為白,背景顏色為黑,繪圖時的黑色方塊就是全形空白 ' ',白色使用 '■',使用 Python 的話,要實作非常簡單:
n = 32
for i in range(n):
for j in range(n):
if i & j == 0:
print('■', end = '')
else:
print(' ', end = '')
print()
這可以畫出以下的圖案:
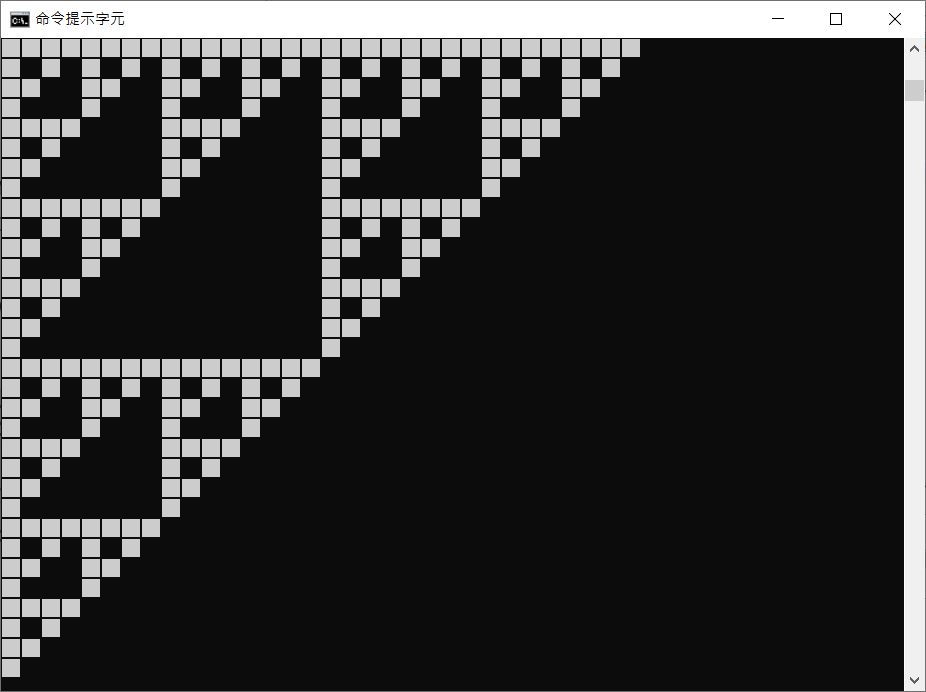
這跟 NumPy 有什麼關係呢?使用 NumPy 不只是呼叫 API 的問題,更重要的是改變運算的想法,這看來只是輸出黑或白的問題,其實可以轉變為如何將需求看成是資料處理,或具體來說,如何在 NumPy 中以陣列運算來實現需求。
就方才的 Python 程式碼輸出來看,最後是個 32 x 32 的平面圖,因此可以先想辦法建立一個 32 x 32 的矩陣,手動寫出來嗎?不!32 只是 n 的一個值,要能依 n 的指定!
NumPy 的 arange 可以指定範圍建立一維陣列,如果想要二維呢?可以建立一個 n * n 長度的一維陣列,然後用 reshape 將它的形狀改變為 n x n 二維陣列:
tri = np.arange(n ** 2).reshape(n, n)
這麼一來,tri 的內容就會是:
[[ 0 1 2 ... 29 30 31]
[ 32 33 34 ... 61 62 63]
[ 64 65 66 ... 93 94 95]
...
[ 928 929 930 ... 957 958 959]
[ 960 961 962 ... 989 990 991]
[ 992 993 994 ... 1021 1022 1023]]
接下來要將陣列中每個元素換為黑或白的字元,為了決定要換成哪個,在先前的虛擬碼中可以看到,需要知道 i 與 j,就 tri 來說,就是每個元素的索引,因此要用兩個迴圈,一個跑 i、一個跑 j…等一下!這麼想你就輸了…XD
想想〈NumPy 與 Matplotlib〉用過 np.sin 函式,可以直接指定 NumPy 陣列給它,傳回一個 NumPy 陣列作為結果,然而不使用迴圈,怎麼實作出這類函式?
NumPy 的 frompyfunc 可以接受一個函式,指定該函式輸入引數的個數,輸出結果的個數,傳回 numpy.ufunc 實例,你指定的函式只需要關切陣列中每個元素該如何處理就可以了,例如:
def bw_symbol(elem, n):
i = elem // n
j = elem % n
return '■' if i & j == 0 else ' '
bw_symbol = np.frompyfunc(bw_symbol, 2, 1)
這麼一來,就可以將 NumPy 陣列指定給傳回的 numpy.ufunc 實例:
tri = bw_symbol(tri, n)
執行以上片段後,tri 會處理成為(\u3000 是全形空白的 Unicode 碼點表示):
[['■' '■' '■' ... '■' '■' '■']
['■' '\u3000' '■' ... '\u3000' '■' '\u3000']
['■' '■' '\u3000' ... '■' '\u3000' '\u3000']
...
['■' '\u3000' '■' ... '\u3000' '\u3000' '\u3000']
['■' '■' '\u3000' ... '\u3000' '\u3000' '\u3000']
['■' '\u3000' '\u3000' ... '\u3000' '\u3000' '\u3000']]
現在,只要將每一列組合為字串,之後輸出字串,就會畫出謝爾賓斯基三角形了,就二維陣列而言,就是沿著 axis 1 運算,這可以使用〈維度、形狀與軸〉中談過的 apply_along_axis,它需要一個函式,因為要將每列組合為字串,因此可以指定 ''.join:
tri = np.apply_along_axis(''.join, 1, tri)
最後將每個字串顯示出來,別急著用迴圈與 print,可以透過 frompyfunc 將 print 向量化:
println = np.frompyfunc(print, 1, 0)
println(tri)
將以上過程整理一下,完整的程式碼就是:
import numpy as np
def bw_symbol(elem, n):
i = elem // n
j = elem % n
return '■' if i & j == 0 else ' '
# 向量化
bw_symbol = np.frompyfunc(bw_symbol, 2, 1)
println = np.frompyfunc(print, 1, 0)
n = 32
tri = np.arange(n ** 2).reshape(n, n)
tri = bw_symbol(tri, n)
tri = np.apply_along_axis(''.join, 1, tri)
println(tri)
看到了嗎?沒有迴圈!其實這也不是有沒有迴圈的問題,整個過程要求的,其實是改變你對需求的看法,從輸出黑白字元的思維,如何轉換為處理陣列資料的想法,才是資料運算、科學運算、資料分析時的關鍵之一。