

Many of us come from object-oriented programming. We are familiar with abstract data types. An abstract data type (ADT) is a mathematical model which encapsulates the data structure and implementation, and only exposes the public interface for interaction. An algebraic data type, however, exposes the data structure and regularity. It can be easily used in a divide-and-conquer context. They are basic elements in the field of functional programming.
(ADT is widely used as the abbreviation of "abstract data type", so it's not used in functional programming. We just use the full name "algebraic data type" directly .)
Java is an object-oriented language, and doesn't support algebraic data types directly. We have two ways to simulate the type. Because an algebraic data type exposes the data structure, we may use a class with public fields to simulate an algebraic data type. However, public fields seem conflicting with many object-oriented principles, so we'll look for the other way. Because an algebraic data type exposes the regularity, the regularity sounds like a behavior. When considering a behavior in Java, an interface is good for defining that.
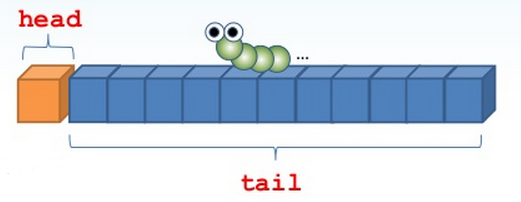
Take a list type for example. We know there's a java.util.List defined in Java SE API, and the List is an abstract data type. If we want to use the algebraic data type model to define a list, how can we do that? In functional programming, a list has a head element and a tail list. If we use an interface to define (or simulate) the list, it will be...
public interface List<T> {
T head();
List<T> tail();
}
One instance of the list is an empty list. Using this interface, we can implement an empty list as..
public class AlgebraicType {
private static List<? extends Object> Nil = new List<Object>() {
public Object head() {
return null;
}
public List<Object> tail() {
return null;
}
public String toString() {
return "[]";
}
};
@SuppressWarnings("unchecked")
public static <T> List<T> nil() {
return (List<T>) Nil;
}
}
private static List<? extends Object> Nil = new List<Object>() {
public Object head() {
return null;
}
public List<Object> tail() {
return null;
}
public String toString() {
return "[]";
}
};
@SuppressWarnings("unchecked")
public static <T> List<T> nil() {
return (List<T>) Nil;
}
}
That is, an empty list has no head and tail. For convenience, we also define a static nil method to return the empty list. After defining an empty list, a list with one element will use the element as the head and Nil as the tail.
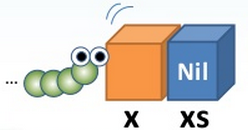
If you have a list xs and want to prepend an element x, the new list can be obtained by using x as the head and xs as the tail.
For convenience, let's define a static con method to create the new list.
public class AlgebraicType {
...
public static <T> List<T> cons(final T x, final List<T> xs) {
return new List<T>() {
private T head;
private List<T> tail;
{ this.head = x; this.tail = xs; }
public T head(){ return this.head; }
public List<T> tail() { return this.tail; }
public String toString() { return head() + ":" + tail(); }
};
}
}
...
public static <T> List<T> cons(final T x, final List<T> xs) {
return new List<T>() {
private T head;
private List<T> tail;
{ this.head = x; this.tail = xs; }
public T head(){ return this.head; }
public List<T> tail() { return this.tail; }
public String toString() { return head() + ":" + tail(); }
};
}
}
Once we have the nil and con methods, a list containing only element 1 can be got from the following code:
cons(1, nil()); // 1:[]
A list containing elements 2 and 1 can be got from the following code:
cons(2, cons(1, nil())); // 2:1:[]
A list containing elements 3, 2 and 1 can be got from the following code:
cons(3, cons(2, cons(1, nil()))); // 3:2:1:[]
For convenience, we define a list method who’s returned list will contains variable arguments.
public class AlgebraicType {
…
@SafeVarargs
public static <T> List<T> list(T... elems) {
if(elems.length == 0) return nil();
T[] remain = Arrays.copyOfRange(elems, 1, elems.length);
return cons(elems[0], list(remain));
}
}
…
@SafeVarargs
public static <T> List<T> list(T... elems) {
if(elems.length == 0) return nil();
T[] remain = Arrays.copyOfRange(elems, 1, elems.length);
return cons(elems[0], list(remain));
}
}
Getting a list with elements 1, 2, 3, and 4 can be as follow:
list(1, 2, 3, 4); // 1:2:3:4:[]
The list defined above is an algebraic data type. It can be divided easily. That is, any list value can only be constructed by two ways. One possible list value is the empty list Nil. Other list values can only be constructed by the head element and the tail list. That's what we said in the beginning, an algebraic data type exposes the data structure and regularity.
Then, why can an algebraic data type be easily used in a divide-and-conquer context? Take the list method for example. It divides the problem into two sub problems.
One sub problem is that you don't provide the list method with any argument. In this situation, the list method just returns the empty list. The other sub problem is that you give the list method one or more arguments. The solution is that, if we can use the first argument as the head element and the remaining arguments as the elements of the tail list, the con method can construct the list which contains all arguments we give.
This leaves us another question: how to get a list which contains the remaining arguments? The list method can call itself recursively with arguments except the first one to get that. As we've mentioned in Functional Programming for Java Developers, Part 1, recursion is just and often a natural form after dividing a problem. While recursion is combined with algebraic data types, it'll become a powerful way to divide problems.