

在能夠進行迴歸與分類之後,就能夠對未來的新資料進行預估的動作,只不過,怎麼確認建立的迴歸、分類模型,能夠很好地進行預測呢?
因為一路上都特意限制變數的數量,以便透過可視化來談迴歸或分類的原理,你可能會想,若是迴歸的話,就將線畫出來,打算用來預測的資料也畫出來,看看是不是座落在迴歸線附近,例如,以〈多項式迴歸〉中的範例來說:
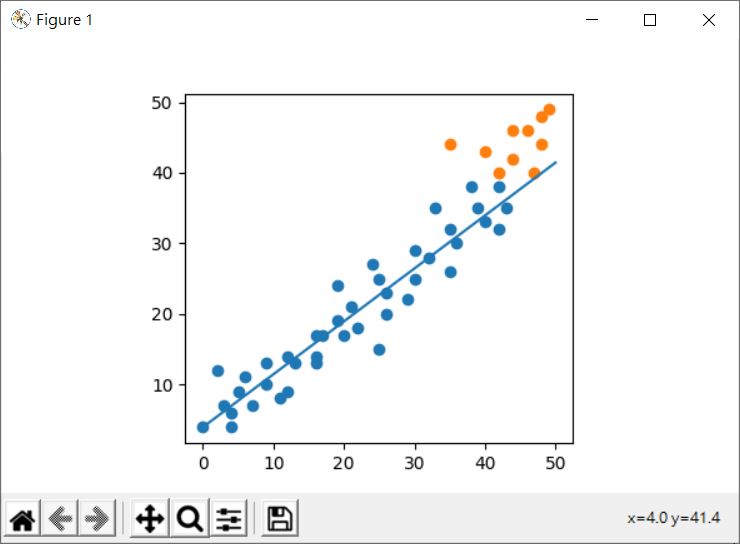
在上圖中,用來計算迴歸的資料佔八成,也就是藍色點的部份,測試資料佔二成,也就是橘色點的部份,單就藍色點部份而言,看來是蠻符合的,可是就橘色點部份來說,顯然有較大的誤差,這種透過學習資料與測試資料來驗證的方式,稱為交叉驗證(Cross validation)。
問題就在於,並不是每次都能很好地透過可視化來呈現結果,例如變數的數量多(也就是高維度)時,是要怎麼可視化,又要怎麼用肉眼觀察預測是否良好呢?
評估迴歸或分類的方式有非常多種,不過,可以從最簡單的誤差計算來認識評估的概念,例如,將測試用的資料代入,求得預估資料,與實際的資料相減求平方和後進行平均:
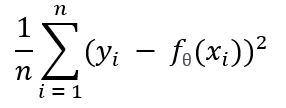
這種方式稱為均方差(Mean Square Error, MSE),若使用 sklearn,可以透過 sklearn.metrics 的 mean_squared_error 來直接計算,例如:
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
def data_from(img_file):
gray = cv2.imread(img_file, cv2.IMREAD_GRAYSCALE)
idx = np.where(gray < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + gray.shape[0] # 反轉 y 軸
sep = data_x.size // 10 * 2
learn_x = data_x[sep:]
learn_y = data_y[sep:]
test_x = data_x[0:sep]
test_y = data_y[0:sep]
return {
'learn' : {'x': data_x[sep:], 'y': data_y[sep:]}, # 計算迴歸用
'test' : {'x': data_x[0:sep], 'y': data_y[0:sep]} # 測試用
}
data = data_from('data.jpg')
plt.gca().set_aspect(1)
plt.scatter(data['learn']['x'], data['learn']['y'])
plt.scatter(data['test']['x'], data['test']['y'])
linreg = LinearRegression() # 負責線性迴歸
# 擬合
linreg = linreg.fit(
data['learn']['x'].reshape((data['learn']['x'].size, 1)), # 符合 fit 要求的形狀
data['learn']['y']
)
# 迴歸線
x = [0, 50]
y = linreg.predict([[0], [50]])
plt.plot(x, y)
predict_y = linreg.predict(data['test']['x'].reshape((data['test']['x'].size, 1)))
# 均方差
plt.text(20, 5,
"MSE: " + str(mean_squared_error(data['test']['y'], predict_y)))
plt.show()
就上例來說,均方差約 60:
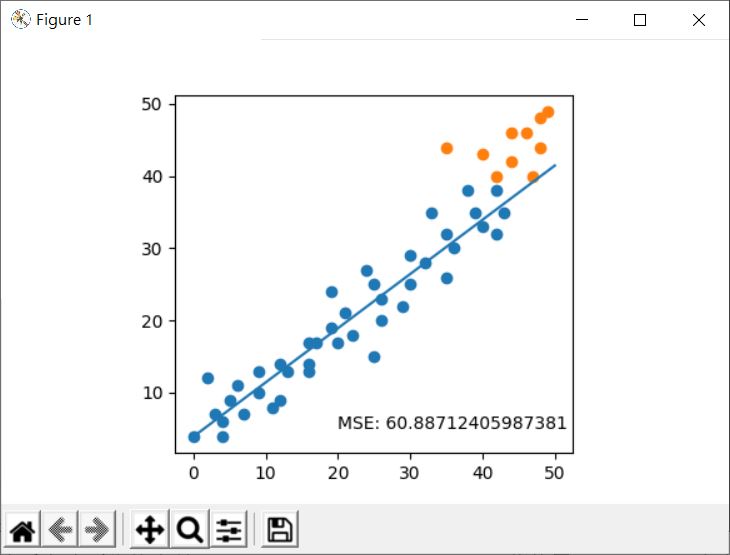
從圖中可以看出,其實迴歸線與測試點之間有蠻大的誤差,若是改為二次多項式來迴歸呢?
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
def data_from(img_file):
gray = cv2.imread(img_file, cv2.IMREAD_GRAYSCALE)
idx = np.where(gray < 127) # 黑點的索引
data_x = idx[1]
data_y = -idx[0] + gray.shape[0] # 反轉 y 軸
sep = data_x.size // 10 * 2
learn_x = data_x[sep:]
learn_y = data_y[sep:]
test_x = data_x[0:sep]
test_y = data_y[0:sep]
return {
'learn' : {'x': data_x[sep:], 'y': data_y[sep:]},
'test' : {'x': data_x[0:sep], 'y': data_y[0:sep]}
}
data = data_from('data.jpg')
plt.gca().set_aspect(1)
plt.scatter(data['learn']['x'], data['learn']['y'])
plt.scatter(data['test']['x'], data['test']['y'])
poly = PolynomialFeatures() # 二次多項式
feature = poly.fit_transform(data['learn']['x'].reshape([data['learn']['x'].size, 1])) # 特徵值
linreg = LinearRegression() # 線性迴歸
linreg = linreg.fit(feature, data['learn']['y']) # 擬合
x = np.linspace(0, 50, 50)
y = linreg.predict(
poly.fit_transform(x.reshape((x.size, 1)))
)
plt.plot(x, y)
predict_y = linreg.predict(poly.fit_transform(data['test']['x'].reshape((data['test']['x'].size, 1))))
plt.text(20, 5, "MSE: " + str(mean_squared_error(data['test']['y'], predict_y)))
plt.show()
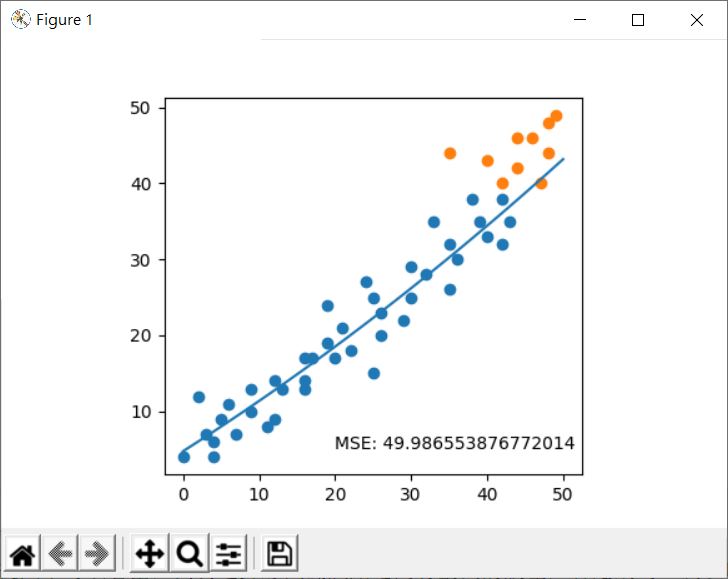
從圖中看來,迴歸線是比較符合測試資料了,然而方才談到了,你不一定能從可視化結果中評估,不過從 MSE 的計算結果來看,49 比方才的 60 少,顯然地,用二次多項式來迴歸是比較合適的。
在分類的評估部份,一個簡單的方式是,測試用資料中,可以被正確分類的資料數,除以測試資料總數,這稱為 Accuracy。
可以正確分類的資料是實際為正而預測為正,這稱為真陽性(True Positive),以及實際為負且預測為負,這稱為真陰性(True Negative),其他則是偽陽性(False Positive)與偽陰性(False Negative),Accuracy 就是 (TP + TN) / (TP + FP + FP + TN):
| 預測\實際 | 正 | 負 |
| :—-: | :—-: | :—-: |
| 正 | TP(True Positive) | FP(False Positive) |
| 負 | FP(False Negative) | TN(True Negative) |
想求得 Accuracy,可以借助 sklearn 的 sklearn.metrics.accuracy_score。
來舉個實際的例子,若〈分類與邏輯迴歸〉中的例子,故意採用感知器來分類,取其中八成為學習資料,二成為測試資料:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
def data_from(csv_file):
data = np.loadtxt(csv_file, delimiter=',')
sep = data.shape[0] // 10 * 2
return {
'learn': data[sep:],
'test': data[:sep]
}
def scatter(data, t_marker, f_marker):
label = data[:,2]
normal_weight = label == 1
overweight = label == 0
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = t_marker)
plt.scatter(data[overweight, 0], data[overweight, 1], marker = f_marker)
data = data_from('height_weight.csv')
# 學習資料
learn_data = data['learn']
scatter(learn_data, 'o', 'x')
learn_height_weight = learn_data[:,0:2]
learn_label = learn_data[:,2]
p = Perceptron()
p.fit(learn_height_weight, learn_label)
coef = p.coef_[0]
intercept = p.intercept_
height = learn_height_weight[:,0]
h = np.arange(np.min(height), np.max(height))
w = -(coef[0] * h + intercept) / coef[1]
plt.plot(h, w, linestyle='dashed') # 分類線
# 測試資料
test_data = data['test']
test_height_weight = test_data[:,0:2]
scatter(test_data, '8', 'X')
pred = p.predict(test_height_weight)
test = test_data[:,2]
plt.text(135, 145, "Accuracy: " + str(accuracy_score(test, pred)))
plt.xlabel('height')
plt.ylabel('weight')
plt.show()
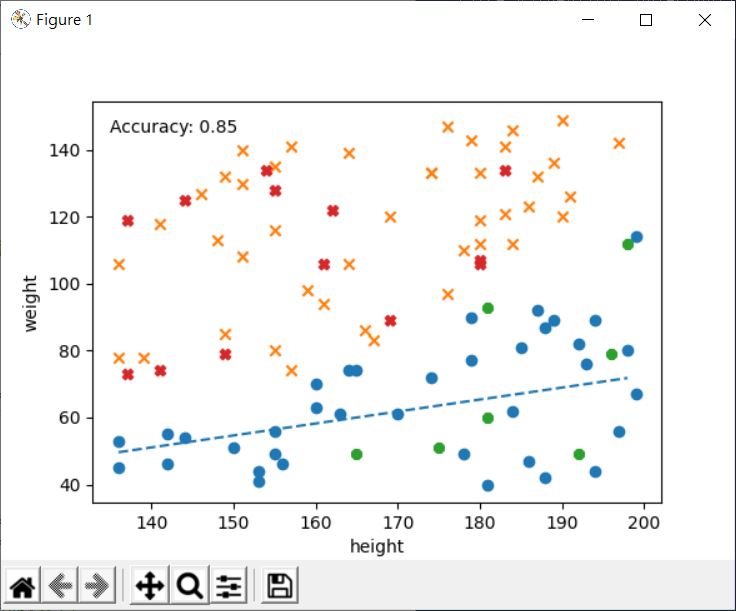
從下圖可以看到,就算只看藍與橘點的學習資料,分類也不準確,而得出來的 Accuracy 是 0.85:
如果使用邏輯迴歸,階數為二的話:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import PolynomialFeatures
def data_from(csv_file):
data = np.loadtxt(csv_file, delimiter=',')
sep = data.shape[0] // 10 * 2
return {
'learn': data[sep:],
'test': data[:sep]
}
def scatter(data, t_marker, f_marker):
label = data[:,2]
normal_weight = label == 1
overweight = label == 0
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = t_marker)
plt.scatter(data[overweight, 0], data[overweight, 1], marker = f_marker)
data = data_from('height_weight.csv')
# 學習資料
learn_data = data['learn']
scatter(learn_data, 'o', 'x')
learn_height_weight = learn_data[:,0:2]
learn_label = learn_data[:,2]
# 邏輯迴歸分類
poly = PolynomialFeatures()
feature = poly.fit_transform(learn_height_weight)
lg_reg = LogisticRegression()
lg_reg.fit(feature, learn_label)
# 分類線
coef = lg_reg.coef_[0]
height = learn_height_weight[:,0]
h = np.arange(np.min(height), np.max(height))
ycoef0 = [coef[5]] * h.size
ycoef1 = coef[2] + coef[4] * h
ycoef2 = coef[0] + coef[1] * h + coef[3] * (h ** 2)
ycoef = np.dstack((ycoef0, ycoef1, ycoef2))[0]
y = np.apply_along_axis(np.roots, 1, ycoef) # 解平方根
w = y[:,1] # 只需要正值部份
plt.plot(h, w, linestyle='dashed')
# 測試資料
test_data = data['test']
test_height_weight = test_data[:,0:2]
scatter(test_data, '8', 'X')
pred = lg_reg.predict( poly.fit_transform(test_height_weight))
test = test_data[:,2]
plt.text(135, 145, "Accuracy: " + str(accuracy_score(test, pred)))
plt.xlabel('height')
plt.ylabel('weight')
plt.show()
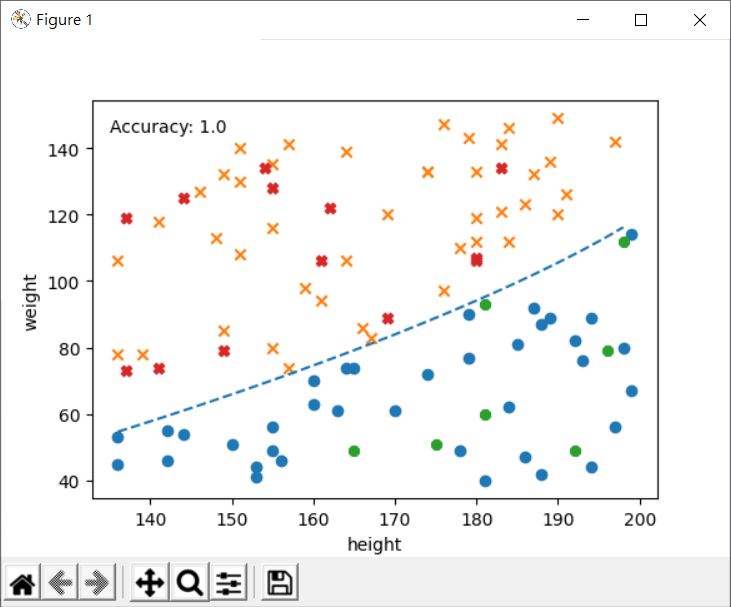
得到的 Accuracy 會是 1.0,就這個簡單的例子來說,就是完全正確地分類了:
實際上,sklearn 提供了 sklearn.model_selection.train_test_split 函式,可以協助畫分學習資料與測試資料(可以透過 test_size 設定比例,該函式還能對資料隨機排序),而 LinearRegression、Perceptron 等,也提供了 score 方法來協助基本評估,有興趣可以看看 API 文件,瞭解其使用方式。
另外在交叉驗證方面,sklearn.model_selection.cross_val_score 提供了實作,可以指定 cv 指定交叉驗證的 fold 數,例如,若 cv 設為 5,表示將資料分為五份,每次取其中一份輪流當測試,其他四份為學習,稱為一個 fold,如此進行五次,取評估結果的平均。
總而言之,必須對預測結果進行評估,這邊談到的 MSE 與 Accuracy 只是眾多評估方式中的兩個,有興趣看看其他的評估方式,就請從機器學習方面的文件或書籍中多做探索了。