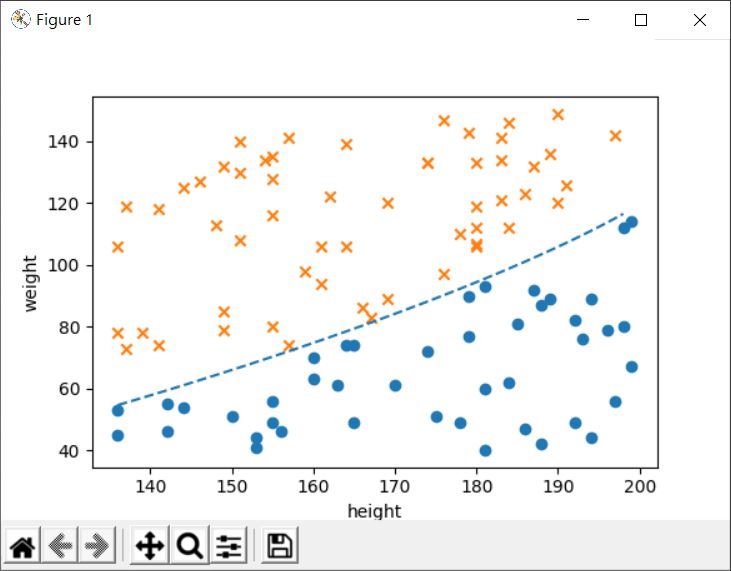
在〈分類與感知器〉中談到感知器的分類原理,是透過直線的法向量旋轉,直到法向量指向的那邊都是同一類,一個有趣的事實是,如果你將原始來源資料,代入求得的直線方程式:
# 都是大於 0
print(coef[0] * data[normal_weight, 0] + coef[1] * data[normal_weight, 1])
# 都是小於 0
print(coef[0] * data[overweight, 0] + coef[1] * data[overweight, 1])
你會發現,其中一類的結果都是大於 0(正常),另一類都是小於 0(胖),這並不是偶然,還記得〈分類與感知器〉中談到的識別函式 fw(x) 嗎?識別函式的輸出,就是根據 W . X 是大於等於 0 或小於 0。
那麼若能找出一條線的程式,讓原始來源資料代入後,可以是大於 0 或小於 0,不就也可以進行分類?是的!從這個觀點出發,最後找出來可以分類的方式,稱為邏輯迴歸(Logistic regression),其名稱中有「迴歸」字眼,是因為在公式推導過程中,有用到迴歸的概念。
sklearn 提供了 sklearn.linear_model.LogisticRegression,可使用邏輯迴歸進行分類,單就線性可分來說,只要將〈分類與感知器〉中的範例程式,從 Perceptron 改為 LogisticRegression 就可以了,例如:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from sklearn.linear_model import LogisticRegression
data = np.loadtxt('height_waist.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
normal_weight = label == 1
overweight = label == -1
# 使用 LogisticRegression
lg_reg = LogisticRegression()
# 提供資料與標記
lg_reg.fit(height_waist, label)
# 取得權重向量
coef = lg_reg.coef_[0]
# 截距
intercept = lg_reg.intercept_
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = 'o')
plt.scatter(data[overweight, 0], data[overweight, 1], marker = 'x')
height = height_waist[:,0]
h = np.arange(np.min(height), np.max(height))
w = -coef[0] / coef[1] * h - intercept
plt.plot(h, w, linestyle='dashed')
plt.show()
求得的方程式,基本上與〈分類與感知器〉中的範例非常接近:
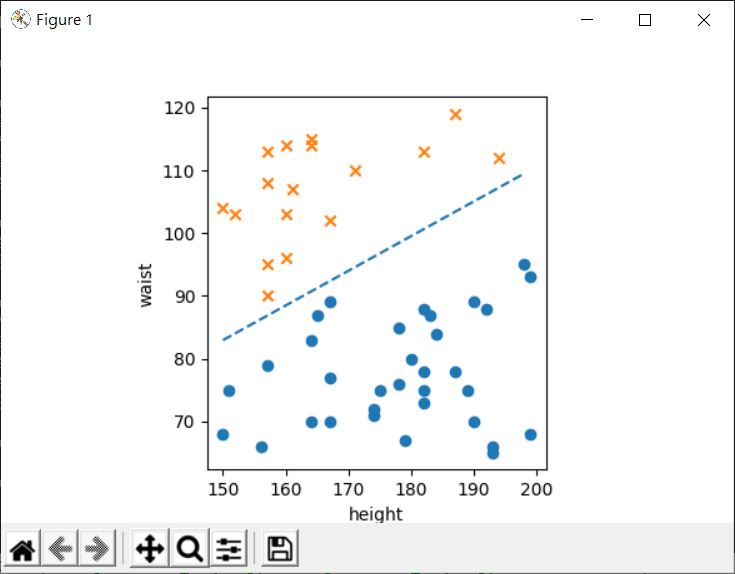
對於非線性可分,可以透過邏輯迴歸來分類,例如,若〈分類與感知器〉中對圖片的標記,每張照片其實還有體重的資訊,若身高、體重與標記存為 height_weight.csv:
155,128,0
183,134,0
181,60,1
161,106,0
144,125,0
181,93,1
...略
如果根據這些資料來畫圖:
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt('height_weight.csv', delimiter=',')
height_weight = data[:,0:2]
label = data[:,2]
plt.xlabel('height')
plt.ylabel('weight')
normal_weight = label == 1
overweight = label == 0
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = 'o')
plt.scatter(data[overweight, 0], data[overweight, 1], marker = 'x')
plt.show()
可以畫出以下的圖形,可以看出來不是線性趨勢:
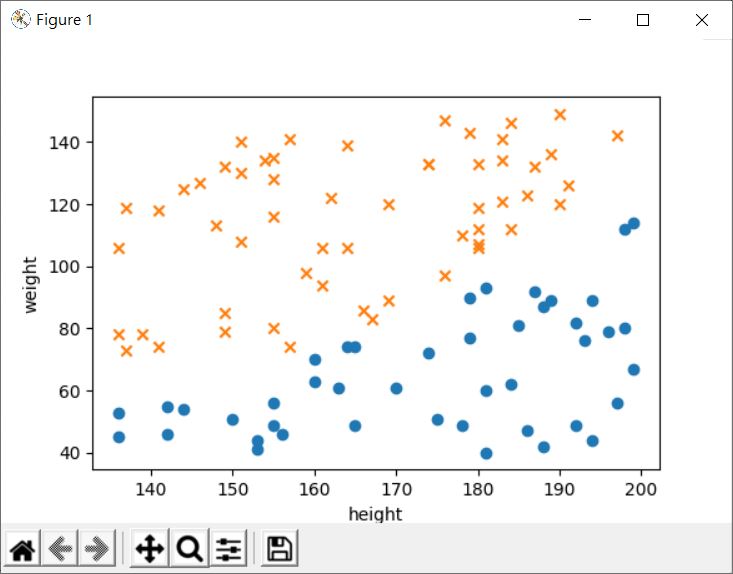
在〈多元線性迴歸(二)〉中看過,結合 PolynomialFeatures 的話,LinearRegression 就可以用來達到多項式迴歸的目的,類似地,PolynomialFeatures 也可以結合 LogisticRegression 使用,例如:
poly = PolynomialFeatures() # 二次多項式
feature = poly.fit_transform(height_weight) # 特徵值
lg_reg = LogisticRegression() # 邏輯迴歸
lg_reg.fit(feature, label)
若只是要預測,可以透過 predict 方法,記得要先用 fit_transform 轉換:
# 顯示 [1. 0.]
print(
lg_reg.predict(
poly.fit_transform([[178, 60], [183, 100]])
)
)
如果要畫圖呢?在〈多元線性迴歸(二)〉中看過,二次的多項式特徵是 (1, x1, x2, x12, x1 * x2, x22),因此,可以透過 LogisticRegression 的 coef_ 取得係數後,結合橫軸值(也就是 x1 的值),整理之後,會是個 x2 的二次多項式,這時透過 numpy 的 roots 求平方根就可以了:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import PolynomialFeatures
data = np.loadtxt('height_weight.csv', delimiter=',')
# height weight
height_weight = data[:,0:2]
label = data[:,2]
poly = PolynomialFeatures() # 二次多項式
feature = poly.fit_transform(height_weight) # 特徵值
lg_reg = LogisticRegression() # 邏輯迴歸
lg_reg.fit(feature, label)
coef = lg_reg.coef_[0]
plt.xlabel('height')
plt.ylabel('weight')
normal_weight = label == 1
overweight = label == 0
plt.scatter(data[normal_weight, 0], data[normal_weight, 1], marker = 'o')
plt.scatter(data[overweight, 0], data[overweight, 1], marker = 'x')
height = height_weight[:,0]
h = np.arange(np.min(height), np.max(height))
ycoef0 = [coef[5]] * h.size
ycoef1 = coef[2] + coef[4] * h
ycoef2 = coef[0] + coef[1] * h + coef[3] * (h ** 2)
ycoef = np.dstack((ycoef0, ycoef1, ycoef2))[0]
y = np.apply_along_axis(np.roots, 1, ycoef) # 解平方根
w = y[:,1] # 只需要正值部份
plt.plot(h, w, linestyle='dashed')
plt.show()
畫出來的圖會是: