

如果你有一組資料,特徵值為 (1, 0)、(0, 1)、(-1, 0)、(0, -1),分別標記為 0、1、0、1,如果分別用 o 與 x 來標示:
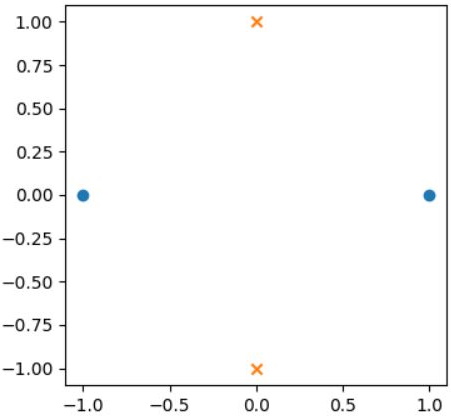
要怎麼畫一條直線分為兩類呢?這顯然不可能!這不是個線性可分的問題;然而如果從另一個角度來想,如果四個點,o 的部份降低,x 的部份昇高又如何呢?例如,特徵值為 (1, 0, -1)、(0, 1, 1)、(-1, 0, -1)、(0, -1, 1):
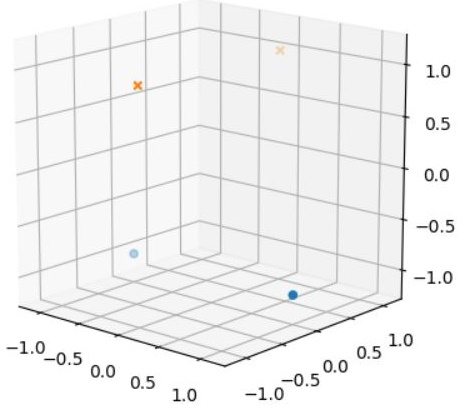
喔!這看來可以用一個平面將之分為兩類了!當然,只有四個點很簡單,如果有很多點呢?例如從 ab.csv 載入的資料:
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt('ab.csv', delimiter=',')
a = data[:,0]
b = data[:,1]
label = data[:,2]
zero = label == 0
one = label == 1
plt.xlabel('a')
plt.ylabel('b')
plt.gca().set_aspect(1)
plt.scatter(a[zero], b[zero], marker = 'o')
plt.scatter(a[one], b[one], marker = 'x')
plt.show()
畫出來的點會是:
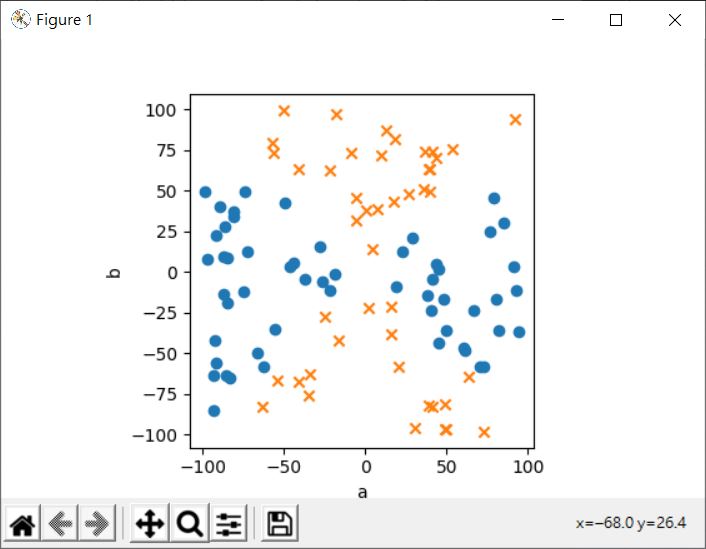
在只有兩類的情況下,寫程式將 o 的部份降低,x 的部份昇高,是也還能應付,只不過如果分類也很多的話,這就行不通了,不能依既有的特徵值想辦法提升維度嗎?還好還好!觀察力敏銳的你,或許發現這可以用個雙抛物面公式:
import numpy as np
import matplotlib.pyplot as plt
# 雙抛物面公式
def f(x, y):
return x ** 2 / 4 - y ** 2 / 4
data = np.loadtxt('ab.csv', delimiter=',')
a = data[:,0]
b = data[:,1]
c = f(a, b)
label = data[:,2]
zero = label == 0
one = label == 1
ax = plt.axes(projection='3d')
ax.set_xlabel('a')
ax.set_ylabel('b')
ax.set_zlabel('c')
ax.set_box_aspect((1, 1, 1))
ax.scatter(a[zero], b[zero], c[zero], marker = 'o')
ax.scatter(a[one], b[one], c[one], marker = 'x')
plt.show()
將它們分為兩群:
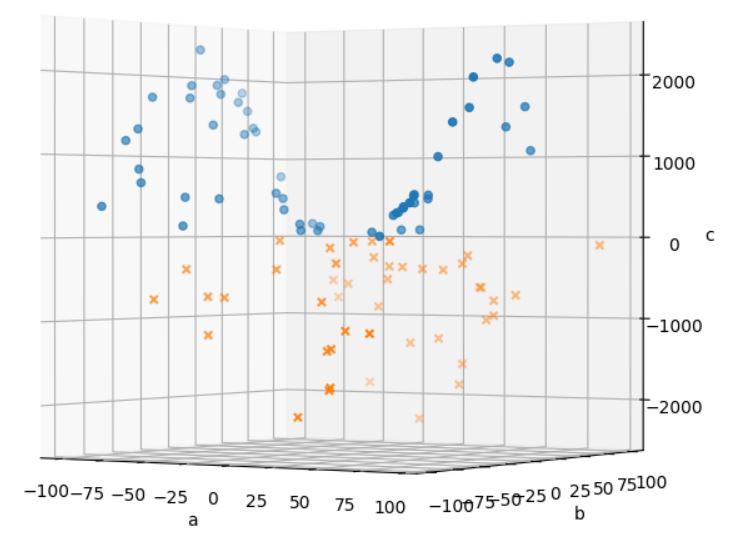
既然如此,不就可以透過這個雙抛物面公式提高維度,然後用提高維度後的資料來進行線性分類嗎?例如:
...續以上的程式碼
X = np.dstack((a, b, c))[0]
na = 10
nb = 20
# 使用感知器
p = Perceptron()
p.fit(X, label)
print(p.predict([[na, nb, f(na, nb)]])) # 預測為 1
這種藉由提高維度,使得一個線性模型可以更好地擬合的作法,你可能並不陌生,還記得〈多元線性迴歸(二)〉中,曾經藉由 PolynomialFeatures 來轉換特徵嗎?當時就有個例子,將 x 提昇至 (1, x, x2)。
理論上,對於一組特徵 X,總是可以找到一個函式 φ(X),可以將 X 轉換至高維度特徵,使得問題成為線性可分,只不過,若特徵數很多時,將這些點各自投影到更高維度,會耗費大量的運算。
仔細想想,其實真正的目的並不是要將 (a, b) 提高維度為 (a, b, f(a, b)),而且要基於訓練資料 (a, b) 來學習分類,提高維度只不過是中間的一個過程,幸運的是,存在著稱為核方法(Kernel method)的技巧,可以在推導過程消除 φ(X)。
假設 A 與 B 是維度相同的向量,A . B 會是純量,φ(A) . φ(B) 也會是個純量,若能找到一個 K 函式,使得 K(A, B) = φ(A) . φ(B),稱 K 為核函數(kernel function),由於核函數的存在,在推導的最終就不需要 φ(x)。
也就是說,有了核函數,可以在既有的維度中進行運算,不用有轉換至高維度的這道手續,有興趣的話,可以自行搜尋相關文件或書籍,瞭解為什麼可以這麼做,只不過核函式到底是什麼呢?這就留在下篇文件再來聊了…