

接續〈核方法(一)〉,核函數必須滿足 K(A, B) = φ(A) . φ(B),有什麼實際的例子呢?嗯…有啊!就 K(A, B) = A . B…
有講等於沒講嗎?其實 K(A, B) = A . B 是最簡單的線性核(Linear Kernel),顯然地,對應的 φ(X) = X,也就是沒有提高維度,直接在既有的維度上學習分類,簡單來說,就相當於沒有用到核方法。
若是 K(A, B) = (A . B)2,則為平方核心(quadratic kernel)的一個例子,例如,若 A 為 (a1, a2),B 為 (b1, b2),K(A, B) = (a1 * b1 + a2 * b2)2,將等號右邊試著計算與重新整理後,可以找出對應的 φ(X) = (x12, x22, sqrt(2) * x1 * x2)。
也就是說,若 A = (a1, a2),φ(A) = (a12, a22, sqrt(2) * a1 * a2),特徵被提高至三維的空間後,a1 * a2 若為正,也就是原本第一或第三象限的特徵,會被提高維度後會是位於第一卦限,a1 * a2 若為負,也就是原本第二或第四象限的特徵,被提高維度後會是會是位於第五卦限。
也就是原本的這些點:
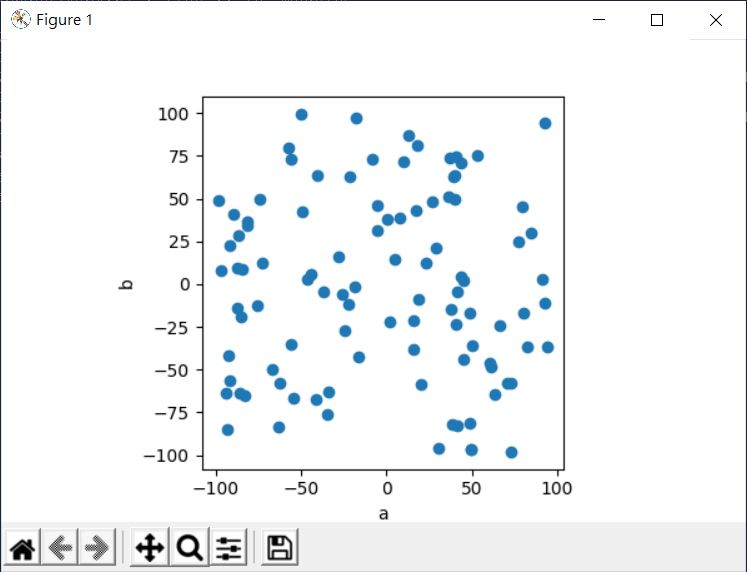
在提高維度之後會變成:
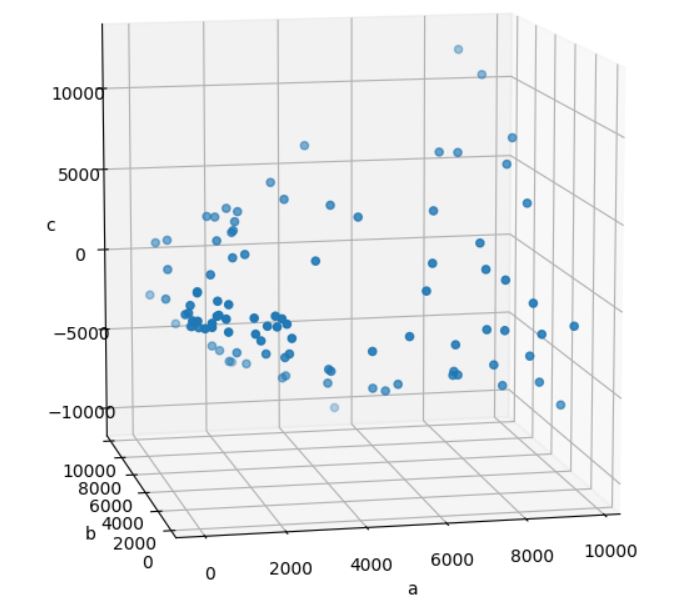
雖然提高維度之後,點分佈投影在圖中的二維平面時,已經不是原本二維資料的點分佈了,然而如果原本第一或第三象限的特徵是一個分類,原本第二或第四象限的特徵是另一個分類,在提高維度之後,從卦限來看,它們依舊可以區別出是兩個分類,
這不就可以用來分類以下的點嗎?
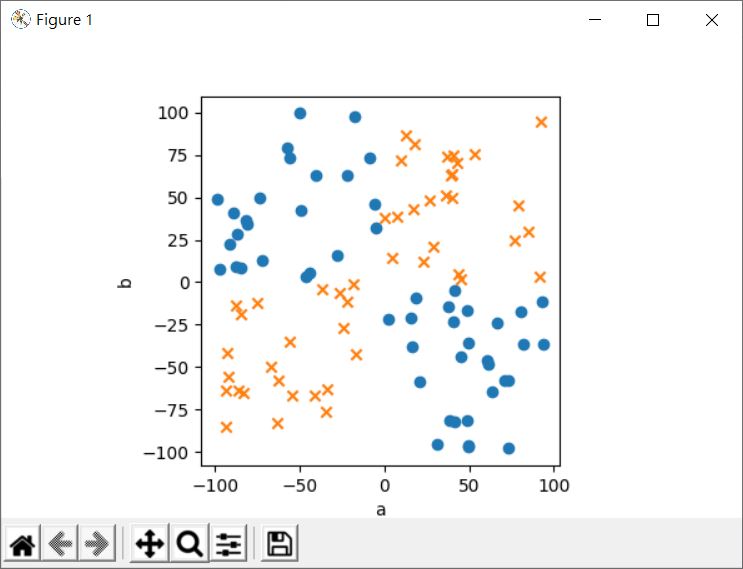
因為點在提昇維度之後,會是這樣:
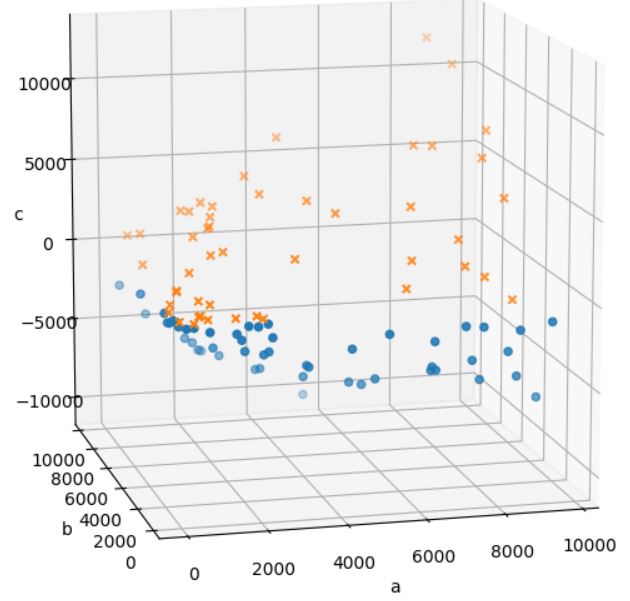
透過以上的方式,可以理解核函數有對應的 φ(X),這有助於你理解與選擇核函數,sklearn.kernel_approximation 提供了運用了核方法的實作,可以在 Kernel Approximation 看到基本說明,不過,相對於單純地隱含 φ(X) 的核方法,sklearn.kernel_approximation 中的實作可以明確地進行維度轉換,也就是你可以取得轉換維度後的特徵。
PolynomialCountSketch 實作了多項式核函數,若 gamma 為 1(預設)、degree 為 2(預設)、coef0 為 0(預設),就是方才看到的平方核心例子,n_components 可以決定維度。
來試著使用以下的程式實現方才提高維度後的圖形(資料 ab2.csv):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.kernel_approximation import PolynomialCountSketch
data = np.loadtxt('ab2.csv', delimiter=',')
a = data[:,0]
b = data[:,1]
label = data[:,2]
zero = label == 0
one = label == 1
# 使用多項式核函數
rbf_feature = PolynomialCountSketch(n_components = 3)
X_features = rbf_feature.fit_transform(data[:,0:2])
aa = X_features[:,0]
bb = X_features[:,1]
cc = X_features[:,2]
ax = plt.axes(projection='3d')
ax.set_xlabel('a')
ax.set_ylabel('b')
ax.set_zlabel('c')
ax.set_box_aspect((1, 1, 1))
ax.scatter(aa[zero], bb[zero], cc[zero], marker = 'o')
ax.scatter(aa[one], bb[one], cc[one], marker = 'x')
plt.show()
這會顯示以下的結果:
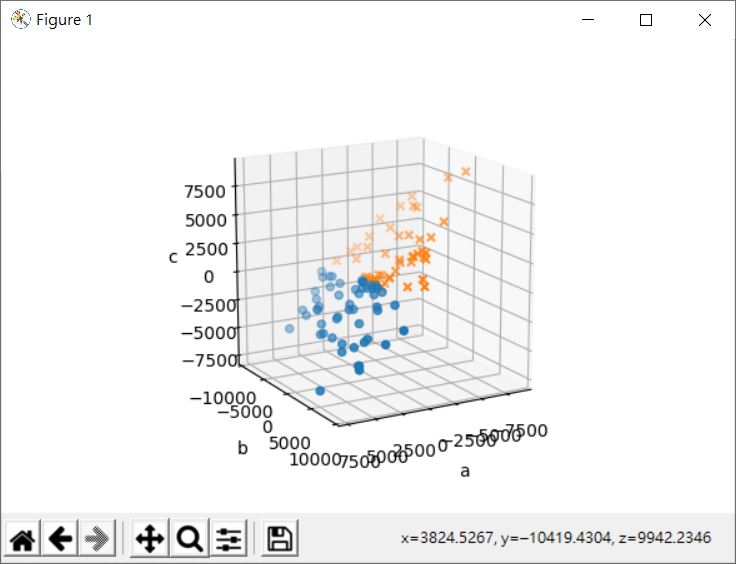
如果要應用在分類時,以下是個簡單的例子:
na = 10
nb = 20
# 使用感知器
p = Perceptron()
p.fit(X_features, label)
print(
p.predict(
rbf_feature.fit_transform([[na, nb]])
)
) # 預測為 1
在應用核方法時,核函數的選擇是個挑戰,出發點應該是觀察資料,認識核函數,再選擇適當的核函數與參數,或者說資料分析本身就是個挑戰,核方法的本質,就是一種認識資料的方式嘛!