

在〈分類與感知器〉的最後談到了,下圖若身高腰圍適中的是藍色,太胖或太瘦是橘色的話,顯然是沒辦法用一條直線來劃分:
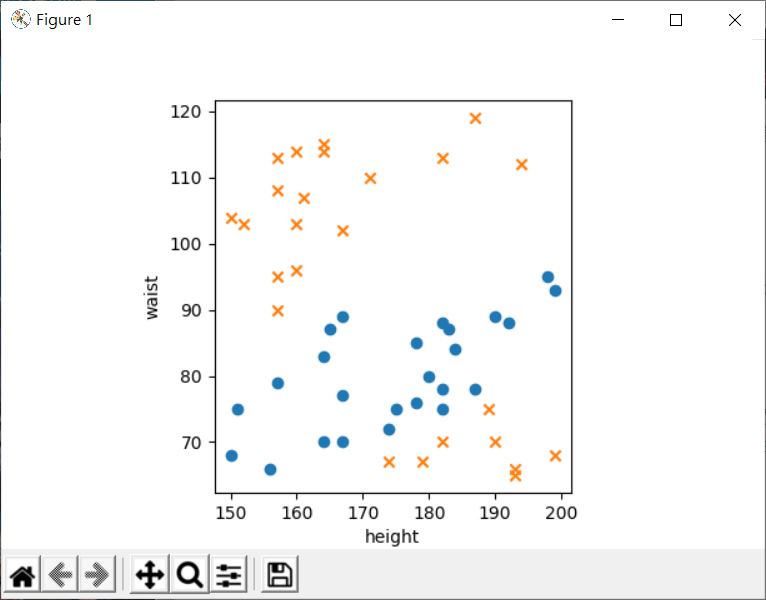
也就是說,只使用一個感知器,是沒辦法對這種狀況進行分類的,然而可以使用多個感知器,分層來解決,當使用到多個感知器且分層的方式時,就進入到類神經網路的範疇,如果試圖去理解類神經網路的原理,基本上就會進入到權重矩陣、偏差矩陣、目標函式、微分等數學運算…
當然,能夠理解原理絕對是件好事,也建議你這麼做,這在理解為何類神經網路能從大量資料中學會分類這件事上,會有很大的幫助,在使用程式庫時,也較易理解程式庫的心智模型(當然,你想實作程式的話,理解原理就更是絕對必要的了)。
不過,如果你已經理解單一感知器的運作原理,倒是可以透過特例,例如〈分類與感知器〉中的身高腰圍範例,來進一步延伸,自行組合多個感知器,來達到想要的預測效果,從中理解為何多個感知器可以運作,避免一開始就迷失在類神經網路的數學推導之中…XD
〈分類與感知器〉中的身高腰圍範例,僅標記是否太胖,那麼沒被標記太胖,是不是就是適中體型呢?不一定吧!如果現在請人們在看照片時,標記胖(-1)、適中(0)、瘦(1),並記錄為:
171,110,-1
157,90,-1
164,115,-1
182,75,0
160,103,-1
199,68,1
152,103,-1
179,67,1
164,83,0
...略
若這些記錄存為 height_waist2.csv,那麼可以使用以下的程式:
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt('height_waist2.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
height = height_waist[:,0]
waist = height_waist[:,1]
normal_weight = label == 0
overweight = label == -1
rundown_weight = label == 1
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(height_waist[normal_weight, 0], height_waist[normal_weight, 1], marker = 'o')
plt.scatter(height_waist[overweight, 0], height_waist[overweight, 1], marker = 'X')
plt.scatter(height_waist[rundown_weight, 0], height_waist[rundown_weight, 1], marker = 'x')
plt.show()
畫出底下的圖:
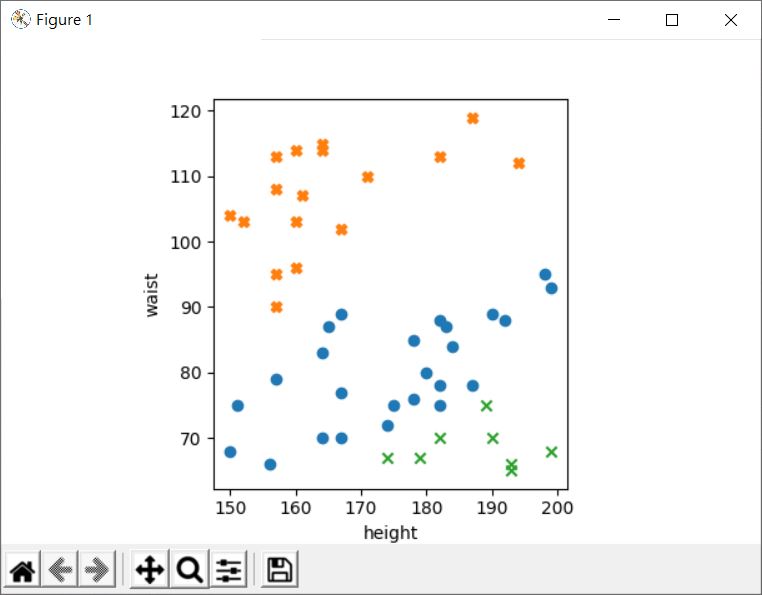
藍色是體型適中,另兩個是太胖與太瘦,現在請你用兩條線,劃開體型適中、太胖與太瘦,也就是:
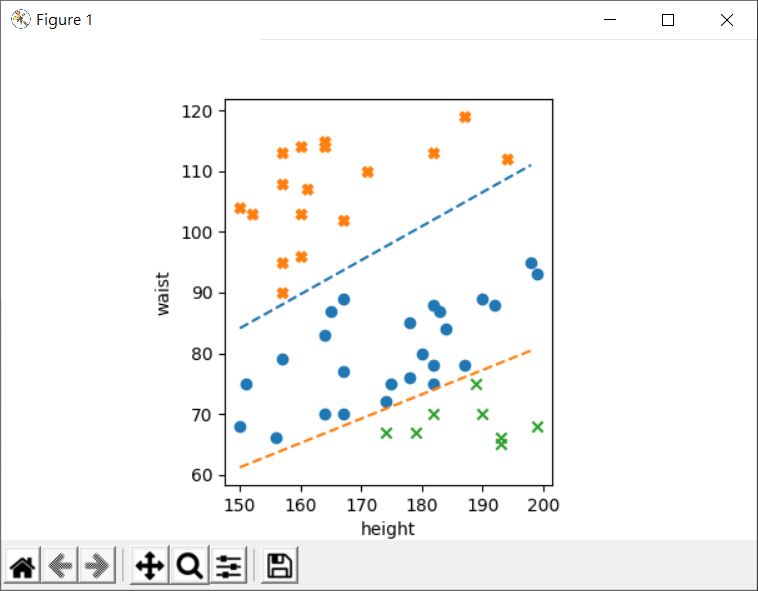
那麼你該怎麼做?一個感知器做不了這件事對吧!既然一個感知器做不了,那就兩個:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
def scatter(height_waist, label):
waist = height_waist[:,1]
normal_weight = label == 0
overweight = label == -1
rundown_weight = label == 1
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(height_waist[normal_weight, 0], height_waist[normal_weight, 1], marker = 'o')
plt.scatter(height_waist[overweight, 0], height_waist[overweight, 1], marker = 'X')
plt.scatter(height_waist[rundown_weight, 0], height_waist[rundown_weight, 1], marker = 'x')
def classify(height_waist, label):
p = Perceptron()
p.fit(height_waist, label)
coef = p.coef_[0]
intercept = p.intercept_
height = height_waist[:,0]
h = np.arange(np.min(height), np.max(height))
w = -(coef[0] * h + intercept) / coef[1]
plt.plot(h, w, linestyle='dashed')
data = np.loadtxt('height_waist2.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
height = height_waist[:,0]
h = np.arange(np.min(height), np.max(height))
scatter(height_waist, label)
# 劃分是否太胖
# 重新標記,只區分太胖(1)與不胖(0)
flabel = label.copy()
flabel[np.where(label == -1)] = 1 # 胖標記為 1
flabel[np.where(label == 1)] = 0 # 瘦也標為 0
classify(height_waist, flabel) # 使用一個感知器分類
# 劃分是否太瘦
# 重新標記,只區分太瘦(1)與不瘦(0)
tlabel = label.copy()
tlabel[np.where(label == 1)] = 1 # 瘦標記為 1
tlabel[np.where(label == -1)] = 0 # 胖也標為 0
classify(height_waist, tlabel) # 使用一個感知器分類
plt.show()
現在有兩個感知器,對於劃分是否太胖的感知器,不胖會標記為 0,對於劃分是否太瘦的感知器,不瘦會標記為 0,顯然地,若兩個感知器的結果都預測為 0,不就是體型適中的那類嗎?
雖然接下來可以直接用條件判斷或 or 來寫,不過,這邊就直接再加個感知器如何?這個感知器有兩個輸入,接受前兩個感知器的輸出(也就是 0 或 1),並透過標記學習:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
def scatter(height_waist, label):
waist = height_waist[:,1]
normal_weight = label == 0
overweight = label == -1
rundown_weight = label == 1
plt.xlabel('height')
plt.ylabel('waist')
plt.gca().set_aspect(1)
plt.scatter(height_waist[normal_weight, 0], height_waist[normal_weight, 1], marker = 'o')
plt.scatter(height_waist[overweight, 0], height_waist[overweight, 1], marker = 'X')
plt.scatter(height_waist[rundown_weight, 0], height_waist[rundown_weight, 1], marker = 'x')
def perceptron(height_waist, label):
p = Perceptron()
p.fit(height_waist, label)
return p
def height_waist_mlp(height_waist, label):
# 劃分是否太胖
# 重新標記,只區分太胖(1)與不胖(0)
flabel = label.copy()
flabel[np.where(label == -1)] = 1 # 胖標記為 1
flabel[np.where(label == 1)] = 0 # 瘦也標為 0
p1 = perceptron(height_waist, flabel) # 建立感知器
# 劃分是否太瘦
# 重新標記,只區分太瘦(1)與不瘦(0)
tlabel = label.copy()
tlabel[np.where(label == 1)] = 1 # 瘦標記為 1
tlabel[np.where(label == -1)] = 0 # 胖也標為 0
p2 = perceptron(height_waist, tlabel) # 建立感知器
# 劃分是否適中
nlabel = label.copy()
# 重新標記,只區分體型不適中(1)與適中(0)
nlabel[np.where(label != 0)] = 1
# 兩個感知器的預測結果
pp_predict = np.dstack((p1.predict(height_waist), p2.predict(height_waist)))[0]
# 提供給第三個感知器
p3 = perceptron(pp_predict, nlabel)
return p1, p2, p3
def predict(mlp, test):
p1, p2, p3 = mlp
pp = np.dstack((p1.predict(test), p2.predict(test)))[0]
return p3.predict(pp)
data = np.loadtxt('height_waist2.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
height = height_waist[:,0]
h = np.arange(np.min(height), np.max(height))
scatter(height_waist, label)
mlp = height_waist_mlp(height_waist, label) # 多層感知器
test = np.array([[190, 95], [180, 119], [189, 65], [168, 76]]) # 測試
pd = predict(mlp, test) # 預測
plt.scatter(test[pd == 0, 0], test[pd == 0, 1], marker = '*')
plt.scatter(test[pd == 1, 0], test[pd == 1, 1], marker = '^')
plt.show()
在顯示的圖形中,測試資料中標示星形是適中體型,三角形則否:
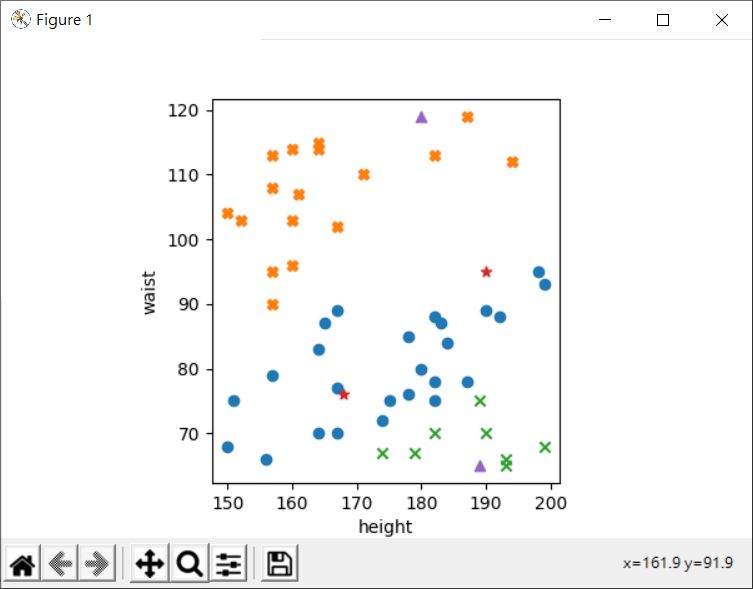
為什麼叫多層感知器呢?因為這三個感知器是這麼銜接的:
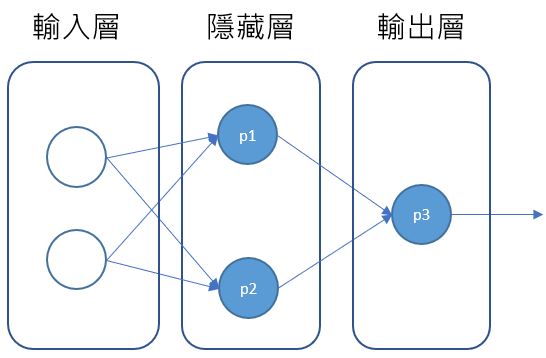
在輸入層的部份,這邊單純就是資料,不過在其他情境中,可能會是另一個輸出層作為來源,如果將方才的 height_waist_mlp 與 predict 作為黑箱,你是不會知道 p1 與 p2 存在的,也就是隱藏層的部份,輸出層就是輸出預測結果。
當然,這邊的多層感知器並不通用,只適用於以上範例,不過用來體會一下,多個感知器彼此間是如何銜接合作是蠻不錯的,也可以透過它來瞭解一下多層感知器的一些概念,這就之後再來討論吧!