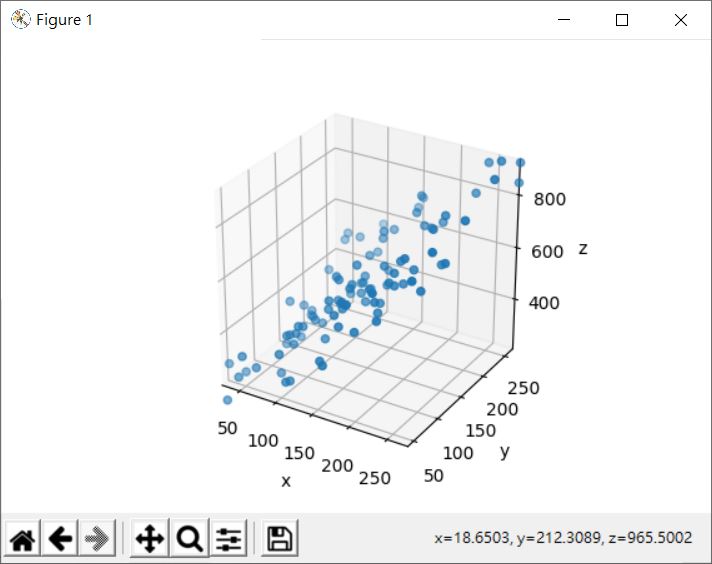
接續〈主成分分析(一)〉,舉個三維降二維的例子,首先是三維資料的視覺化:
import numpy as np
import cv2
import matplotlib.pyplot as plt
def points(start, end, step, noise, f):
n = (end - start) // step
x = np.arange(start, end, step) + np.random.rand(n) * noise
y = np.arange(start, end, step) + np.random.rand(n) * noise
z = f(x, y) + np.random.rand(n) * noise
return np.dstack((x, y, z))[0]
# 用來產生資料的平面函式
def f(x, y):
return 2 * x + y + 10
# 資料來源
data = points(0, 100, 1, 200, f)
ax = plt.axes(projection='3d')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_box_aspect((1, 1, 1))
ax.scatter(data[:,0], data[:,1], data[:,2])
plt.show()
這會顯示以下的結果:
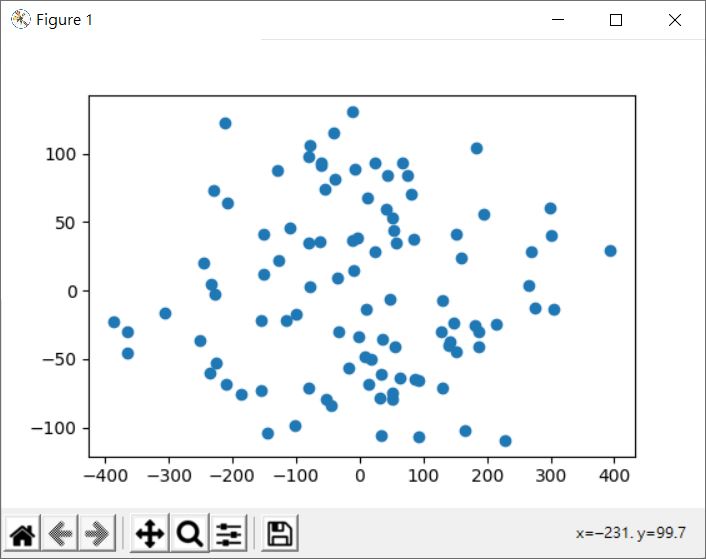
降為二維的話,就是投影在某個平面後的結果,用二維散佈圖畫出來就是:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
def points(start, end, step, noise, f):
n = (end - start) // step
x = np.arange(start, end, step) + np.random.rand(n) * noise
y = np.arange(start, end, step) + np.random.rand(n) * noise
z = f(x, y) + np.random.rand(n) * noise
return np.dstack((x, y, z))[0]
# 用來產生資料的平面函式
def f(x, y):
return 2 * x + y + 10
# 資料來源
data = points(0, 100, 1, 200, f)
# 降為二維
pca = PCA(n_components = 2)
transformed = pca.fit_transform(data)
plt.scatter(transformed[:,0], transformed[:,1])
plt.show()
這會顯示以下的結果:
這邊沒有對三維資料做分析,單純就只是設定 n_components,讓資料降為二維,這不見得是好的選擇,n_components 可以設為 'mle',這時會根據 Maximum Likelihood Estimation 來估算適合的成分數;n_components 也可以設定 0 到 1 間的值,表示主成分的比例閥值,也就是有 n 個成分的比例相加後大於閥值,就將 n_components 設為 n。
話說投影是投影,投影前的資料會有什麼相關性,投影後的資料是不是有利於找出相關性,還是要靠自己來辨別,一個有趣的例子是,將圖片資料投影至三維?
import numpy as np
import cv2
import matplotlib.pyplot as plt
from matplotlib.pyplot import cm
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
digits = load_digits()
pca = PCA(3) # 將 64 維投影至 3 維
projected = pca.fit_transform(digits.data)
ax = plt.axes(projection='3d')
ax.set_xlabel('component 1')
ax.set_ylabel('component 2')
ax.set_zlabel('component 3')
ax.set_box_aspect((1, 1, 1))
p = ax.scatter(
projected[:,0], projected[:,1], projected[:,2],
c = digits.target, # 指定標記
edgecolor = 'none', # 無邊框
alpha = 0.5, # 不透明度
cmap = plt.cm.get_cmap('nipy_spectral', 10) # 依標記著色
)
plt.gcf().colorbar(p) # 著色圖例
plt.show()
上圖將〈sklearn.datasets 資料集〉手寫數字圖片 8x8 維降至 3 維,然後繪製散佈圖,並依原標記來著色,這能觀察出什麼關係呢?
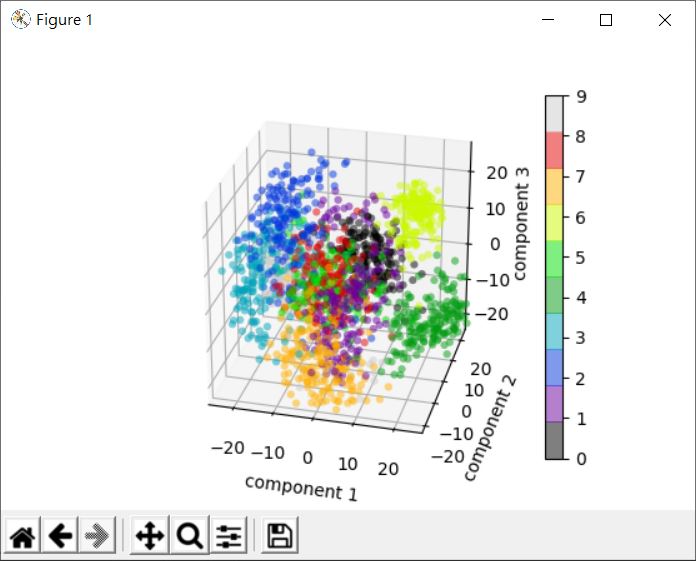
有趣!代表同一數字的圖片,有一種物以類聚的傾向,這代表著,可以透過一些方式來將這些圖片分類,在〈sklearn.datasets 資料集〉中也示範過怎麼對手寫圖片分類了!
就這邊的手寫圖片範例來說,如果降為二維呢?
import numpy as np
import cv2
import matplotlib.pyplot as plt
from matplotlib.pyplot import cm
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
digits = load_digits()
pca = PCA(2) # 將 64 維投影至 2 維
projected = pca.fit_transform(digits.data)
plt.xlabel('component 1')
plt.ylabel('component 2')
plt.scatter(
projected[:,0], projected[:,1],
c = digits.target, # 指定標記
edgecolor = 'none', # 無邊框
alpha = 0.5, # 不透明度
cmap = plt.cm.get_cmap('nipy_spectral', 10) # 依標記著色
)
plt.colorbar()
plt.show()
可以畫出以下的圖形:
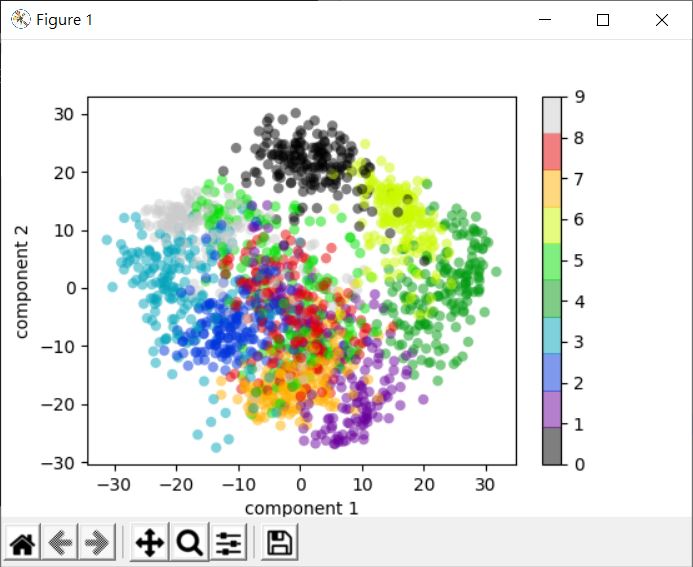
由於相對於三維又多降了一個維度,雖然還是可以觀察出物以類聚,不過顯然有更多的重疊部份,某些程度上這表示維度降過頭了,對後續資料處理可能會造成問題之類的…
透過 PCA 降維後的資料,是想試著將原資訊組成成分中較不重要的部份捨去,也就是對於最終想辨別的任務沒有幫助的部份,例如手寫圖片中若有雜訊,以人類來辨別時,主要成分就是符合數字的部份,不重要的就是雜訊的部份,那麼若 PCA 降維適當,是否可用來去除雜訊呢?
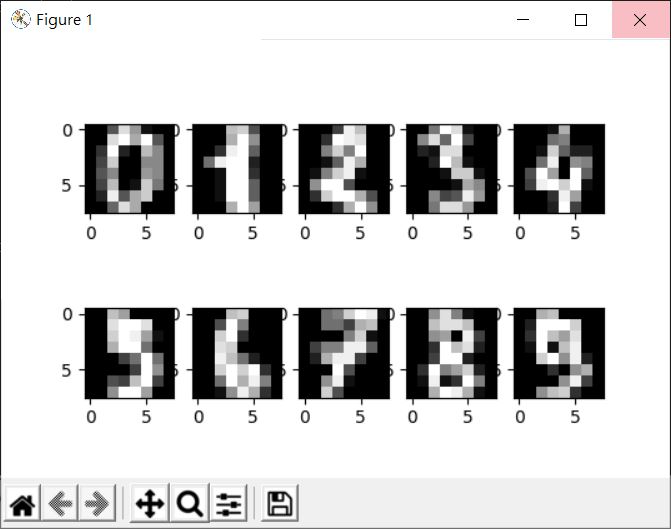
例如,在〈sklearn.datasets 資料集〉中,看到的數字圖片是:
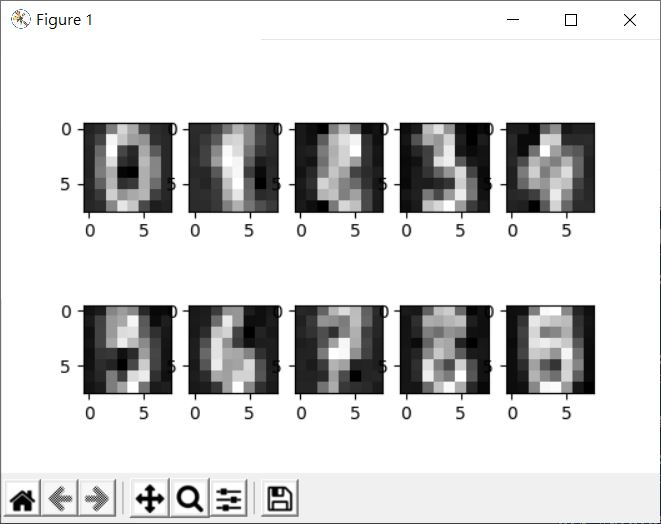
如果加入一些雜訊呢?
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
digits = load_digits()
noisy = np.random.normal(digits.data, 3) # 加入高斯雜訊
plt.gray()
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(noisy[i].reshape((8, 8)))
plt.show()
看來是有些雜訊了:
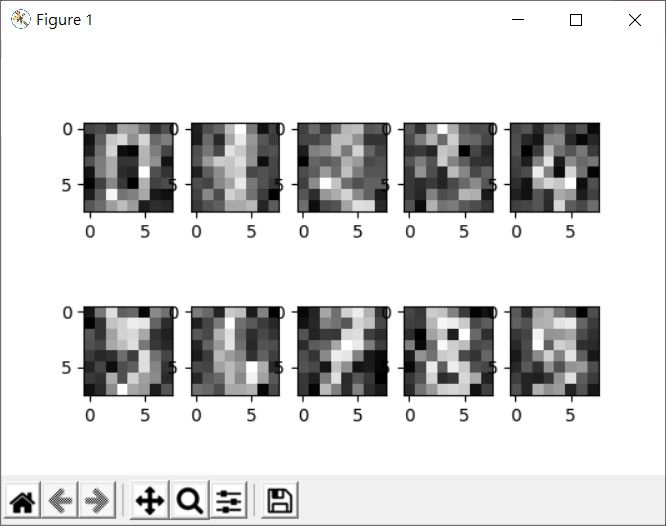
來試著用 PCA 去除雜訊:
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
digits = load_digits()
noisy = np.random.normal(digits.data, 3)
pca = PCA(0.5) # 0.5 是試誤出來的 XD
transformed = pca.fit_transform(noisy)
inversed = pca.inverse_transform(transformed)
plt.gray()
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(inversed[i].reshape((8, 8)))
plt.show()
效果呢?勉勉強強 … XD