

在〈NumPy 擴張機制(一)〉中談到了擴張機制的基本原理,對於使用者而言,運用擴張機制時以直覺易懂容易撰寫就可以了,例如,底下都是很直覺的寫法:
import numpy as np
a = np.array([1, 2, 3]) + 1
b = np.array([[1, 2, 3], [4, 5, 6]]) + 1
c = np.array([[1, 2, 3], [4, 5, 6]]) + np.array([1, 2, 3])
d = np.array([[1, 2, 3], [4, 5, 6]]) + np.array([[1], [2]])
e = np.arange(3 ** 3).reshape(3, 3, 3) + np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
以上運算時,擴張的方式應該不難想像,例如,下圖中右側紅色是原來的左運元,白色是運算時必須擴充的部份:
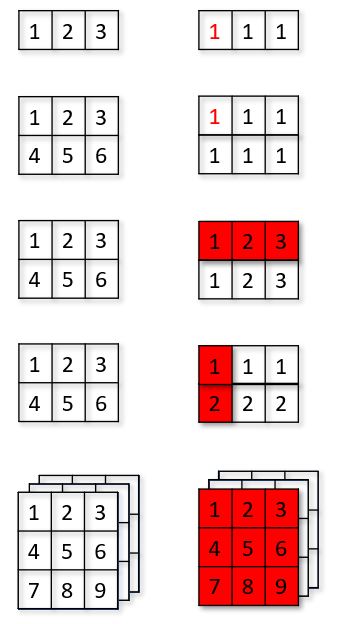
有些場合的底層也運用了擴張,例如〈NumPy 陣列索引〉中談到的 np.ix_,實際上不透過 np.ix_,也可以自行透過陣列索引指定,得到叉積的結果,其實就使用者而言,沒必要探究這該怎麼做,以下純綷個人研究…
先複習一下〈NumPy 陣列索引〉談到的,NumPy 的 [] 可以指定索引陣列:
>>> a = np.arange(1, 6)
>>> a[[0, 1, 4]]
array([1, 2, 5])
>>>
〈NumPy 陣列索引〉也談到,多維陣列時,可以有多個索引陣列,使用逗號區隔,表示 axis 的分隔:
>>> a = np.arange(25).reshape((5, 5))
>>> a[[0, 1, 4], [0, 3, 4]]
array([ 0, 8, 24])
>>>
[0, 1, 4], [0, 3, 4] 其實是一組彼此搭配的索引陣列,然而可能跟純量索引或範圍的指定混淆,誤以為是 [0, 1, 4] 與 [0, 3, 4] 的交叉(叉積),為了避免混淆,可以加上括號建立 tuple:
>>> a[([0, 1, 4], [0, 3, 4])] # 相當於 a[tuple([[0, 1, 4], [0, 3, 4]])]
array([ 0, 8, 24])
>>>
因此對於:
>>> a = np.arange(1, 6)
>>> a[[0, 1, 4]]
array([1, 2, 5])
>>>
若要更清楚表示,可以寫為…
>>> idx_arr = ([0, 1, 4], )
>>> a[idx_arr]
array([1, 2, 5])
>>>
(idxarr1, idxarr2, ...) 提供的資料,其實會用來計算出最後的索引陣列,它的形狀,決定了輸出陣列的形狀,而其中的元素,必須作為索引存取來源陣列。
就 ([0, 1, 4], ) 而言,最後的索引陣列當然是 [0, 1, 4],形狀是 (3, ),因而最後輸出陣列形狀會是 (3, ),而索引陣列元素 0、1、4,可以作為索引存取 a,結果就是 [1, 2, 5],這沒有問題,當然,你也可以寫 a[[0, 1, 2, 3, 3, 2, 1]],這會得到 [1 2 3 4 4 3 2]。
如果將 idx_arr 是 ([[0, 1, 4]], ) 呢?索引陣列的形狀是 (1, 3),而索引陣列元素 0、1、4,取出了 a[0]、a[1]、a[4],最後結果就是 [[a[0], a[1], a[4]]],也就是 [[1 2 5]]。
類似地,如果 idx_arr 是 ([[0, 1, 2], [1, 3, 4], [2, 3, 1]], ),最後的輸出陣列就會是 [[a[0], a[1], 2], [a[1], a[3], a[4]], [a[2], a[3], a[1]]],也就是得到:
[[1 2 3]
[2 4 5]
[3 4 2]]
方才談到,(idxarr1, idxarr2, ...) 提供的資料,會用來計算出最後的索引陣列,其中的元素,必須作為索引存取來源陣列,也就是說,如果你提供了 n 個索引陣列,你的陣列來源就是必須是 n 維,例如,在二維陣列時,可以使用兩個索引陣列:
>>> a = np.arange(25).reshape((5, 5))
>>> idx_arr = ([0, 1, 4], [0, 3, 4])
>>> a[idx_arr]
array([ 0, 8, 24])
>>>
最後的索引陣列相當於 [[0, 0], [1, 3], [4, 4]](類似 zip 的結果),結果就是 [a[0, 0], a[1, 3], a[4, 4]],也就是 [0, 8, 24]。
有沒有辦法用 (idxarr1, idxarr2) 取得叉積呢?那麼,計算後的索引陣列最後的形狀,必須是二維才行,我們一步一步來,首先:
import numpy as np
a = np.arange(25).reshape((5, 5))
idx_arr = ([0, 1, 4], [0])
print(a[idx_arr])
提供的兩個索引陣列形狀不同,這時擴張機制運作了,第二個陣列 [0] 變成了 [0, 0, 0],結果得到 [[0, 0], [1, 0], [4, 0]],最後結果是 [0, 5, 20]。
相對地,底下提供了 ([0], [0, 3, 4]):
import numpy as np
a = np.arange(25).reshape((5, 5))
idx_arr = ([0], [0, 3, 4])
print(a[idx_arr])
第一個陣列 [0] 擴張後變成了 [0, 0, 0],結果得到了 [[0, 0], [0, 3], [0, 4]],結果就是 [0, 3, 4]。
如果是這個呢?
import numpy as np
a = np.arange(25).reshape((5, 5))
idx_arr = ([[0]], [0, 3, 4])
print(a[idx_arr])
[[0]] 的形狀是 (1, 1),[0, 3, 4] 形狀為 (3,),後者擴張成為 (1, 3),也就是 [[0, 3, 4]],現在維度相同了,處理同一層的部份,也就是 [0] 與 [0, 3, 4],依上頭談到的,結果得到了 [[0, 0], [0, 3], [0, 4]],也就是最後計算出來的索引陣列會是 [[[0, 0], [0, 3], [0, 4]]],最後輸出的陣最形狀會是 (1, 3),相當於 [[a[0, 0], a[1, 3], a[4, 4]]],也就是 [[0 3 4]]。
方才範例的 [0, 3, 4] 擴張後會成為 [[0, 3, 4]],因此如下直接寫 [[0, 3, 4]] 也可以:
import numpy as np
a = np.arange(25).reshape((5, 5))
idx_arr = ([[0]], [[0, 3, 4]])
print(a[idx_arr])
既然如此,那如果寫以下,不就可以得到叉積的結果?
import numpy as np
a = np.arange(25).reshape((5, 5))
idx_arr = ([[0], [1], [4]], [[0, 3, 4]])
print(a[idx_arr])
最後,[0] 會與 [0, 3, 4] 計算索引陣列得到 [[0, 0], [0, 3], [0, 4]],[1] 會與 [0, 3, 4] 計算索引陣列得到 [[1, 0], [1, 3], [1, 4]],[4] 會與 [0, 3, 4] 計算索引陣列得到 [[4, 0], [4, 3], [4, 4]],最後得到的索引陣列就是:
[
[[0, 0], [0, 3], [0, 4]],
[[1, 0], [1, 3], [1, 4]],
[[4, 0], [4, 3], [4, 4]]
]
最內層的 [0, 0] 等會用來存取來源陣列,因而得到的才會是叉積的結果,觀察一下以上的過程,若指定了 [a, b, c]、[e, f, g],將之轉換為 [[a], [b], [c]], [[e, f, g]] 不就好了?這就是 np.ix_ 做的事囉!
import numpy as np
print(np.ix_([0, 1, 4], [0, 3, 4]))
上例會顯示:
(array([[0],
[1],
[4]]), array([[0, 3, 4]]))
這純綷就是探究陣列索引、擴張機制與 np.ix_ 之間的關係罷了,就叉積而言,直接使用 np.ix_ 就可以了,當然,若能掌握陣列索引、擴張機制,就可以依需求來處理資料,太複雜的陣列索引、擴張機制,就封裝個函式,取個好名稱以方便使用。