

對於經常面對 Excel 或資料庫表格的人來說,面對 Pandas 的 DataFrame 應該會感到熟悉,基本上,它就是用來表現二維的表格資料,例如,簡單的成績記錄在 Excel 可能是這麼記錄:
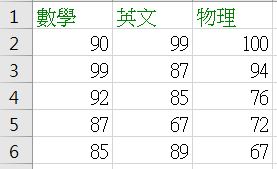
使用 Pandas 的話,可以透過 DataFrame 來建立對應的資料:
import pandas as pd
scores = pd.DataFrame({
'數學' : [90, 99, 92, 87, 85],
'英文' : [99, 87, 85, 67, 89],
'物理' : [100, 94, 76, 72, 67]
})
print(scores)
這會顯示以下的結果:
數學 英文 物理
0 90 99 100
1 99 87 94
2 92 85 76
3 87 67 72
4 85 89 67
如果不想透過 dict,也可以透過個別指定行(Column)資料的方式來建立 DataFrame,這在程式碼的視覺上,會比較像是 Excel 之類的表格:
import pandas as pd
scores = pd.DataFrame(
[
[90, 99, 100],
[99, 87, 94],
[92, 85, 76],
[87, 67, 72],
[85, 89, 67]
],
columns = ['數學', '英文', '物理']
)
print(scores)
顯示結果中最左邊顯示的是索引,就跟〈一維的 Series〉中類似的,DataFrame 的索引名稱是可以修改的,修改時也是透過 index,沒有指定的話,就自動從 0 開始編號作為索引名稱,類似地,如果上例沒有指定 columns,也是自動從 0 開始編號作為索引名稱,如果 columns 指定的數量大於資料,資料部份會自動設為:
底下的範例同時指定了 columns 與 index:
import pandas as pd
scores = pd.DataFrame(
[
[90, 99, 100],
[99, 87, 94],
[92, 85, 76],
[87, 67, 72],
[85, 89, 67]
],
columns = ['數學', '英文', '物理'],
index = ['No.01', 'No.02', 'No.03', 'No.04', 'No.05'],
)
print(scores)
這會顯示以下的結果:
數學 英文 物理
No.01 90 99 100
No.02 99 87 94
No.03 92 85 76
No.04 87 67 72
No.05 85 89 67
若與 NumPy 二維陣列對比,DataFrame 的 index 相當於軸 0 索引,而 columns 相當於軸 1 索引,然而可以給予更具體的名稱。
DataFrame 的資料,也可以套用〈Universal 函式〉,例如全部分數減 5:
print(scores - 5)
結果會顯示以下:
數學 英文 物理
No.01 85 94 95
No.02 94 82 89
No.03 87 80 71
No.04 82 62 67
No.05 80 84 62
如果想取得某行的資料,可以透過索引名稱。例如:
print(scores['數學'])
也可以寫為 scores.數學,在只有指定一行時,結果會以 Series 傳回,因而會顯示以下:
0 90
1 99
2 92
3 87
4 85
Name: 數學, dtype: int64
若要指定兩個以上的行,可以透過 list。例如:
print(scores[['數學', '物理']])
若指定的行是兩行以上,結果會以 DataFrame 傳回,因而會顯示以下結果:
數學 物理
0 90 100
1 99 94
2 92 76
3 87 72
4 85 67
若要取得某列的話,必須透過 DataFrame 的 loc 指定索引名稱。例如,取得 'No.02' 的資料:
print(scores.loc['No.02'])
當指定的列只有一行時,會以 Series 傳回,會顯示以下的結果:
數學 99
英文 87
物理 94
Name: No.02, dtype: int64
如果要指定多列的話,可以透過 list。例如:
print(scores.loc[['No.02', 'No.04']])
若指定的行是兩行以上,結果會以 DataFrame 傳回,因而會顯示以下結果:
數學 英文 物理
No.02 99 87 94
No.04 87 67 72
loc 也可以同時指定列、行,中間以逗號區隔,例如 No.01 列的 '數學' 行:
print(scores.loc['No.01', '數學']) # 顯示 90
實際上這只指定了一個元素,對於對象會是一個元素的情況,建議使用 at:
print(scores.at['No.01', '數學']) # 顯示 90
loc 的應用場合在於指定多列多行,例如:
print(scores.loc[['No.01', 'No.03'], ['數學', '物理']])
這會顯示以下結果:
數學 物理
No.01 90 100
No.03 92 76
在某些場合,你可能想要一整個範圍的列或行,這可以透過 iloc,i 表示整數索引,這可以實現〈NumPy 陣列索引〉中的 np.ix_ 的效果。例如:
print(scores.iloc[0:3,1:3])
這會顯示以下的結果:
英文 物理
No.01 99 100
No.02 87 94
No.03 85 76
類似地,at 也有個對應的 iat,可以指定數字索引;如果是 scores.iloc[0:3],也可以簡寫為 scores[0:3]。
〈NumPy 陣列索引〉看到的布林索引,也是行得通的,例如,找出數學大於 90 分的資料:
print(scores[scores.數學 > 90])
這會顯示以下的結果:
數學 英文 物理
No.02 99 87 94
No.03 92 85 76
或者是找出物理小於 80 的物理分數:
print(scores.loc[scores.物理 < 80, '物理'])
這會顯示以下的結果:
No.03 76
No.04 72
No.05 67
Name: 物理, dtype: int64
可以就以上的試著多做一些嘗試與變化,做出各種不同的資料組合取法。