接續〈K-means 分群(一)〉,來看看另一個例子,在〈主成分分析(二)〉中看過,〈sklearn.datasets 資料集〉中的手寫數字圖片,灰階像素的特徵降維為三維後,具有群聚的現象,這暗示著灰階像素的特徵具有某種距離的概念?來試著驗證看看:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from matplotlib.pyplot import cm
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
digits = load_digits()
pca = PCA(3) # 將 64 維投影至 3 維
projected = pca.fit_transform(digits.data)
# 透過 KMeans 分群
kmeans = KMeans(n_clusters = 10)
kmeans.fit(digits.data)
target = kmeans.predict(digits.data)
ax = plt.axes(projection='3d')
ax.set_xlabel('component 1')
ax.set_ylabel('component 2')
ax.set_zlabel('component 3')
ax.set_box_aspect((1, 1, 1))
p = ax.scatter(
projected[:,0], projected[:,1], projected[:,2],
c = target, # 指定 K-means 分群結果作為標記
edgecolor = 'none', # 無邊框
alpha = 0.5, # 不透明度
cmap = plt.cm.get_cmap('nipy_spectral', 10) # 依標記著色
)
plt.gcf().colorbar(p) # 著色圖例
plt.show()
這邊在著色時,使用的是 KMeans 分群後的結果,來看看畫出來的樣子:
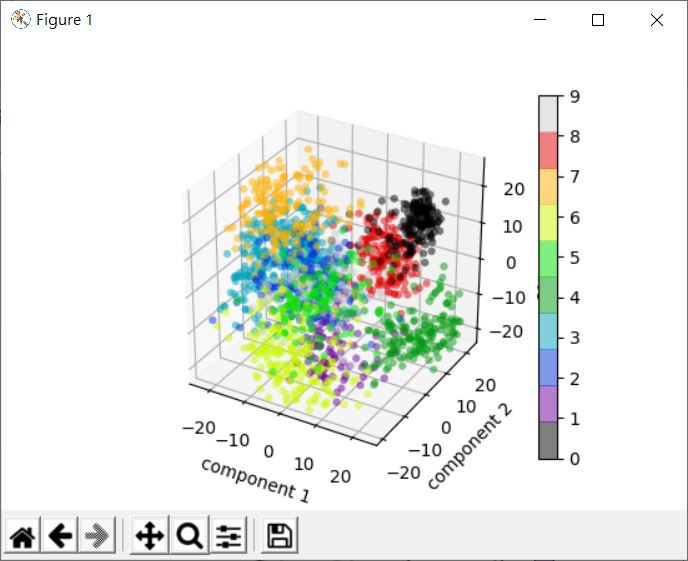
看來分群大致上是符合〈主成分分析(二)〉中的散佈圖結果,只不過每個群各是代表哪個數字,當然是不知道的…
另一個問題是,資料該分為幾群比較適合,例如,若事先不知道圖片代表 10 個手寫數字,該怎麼指定適當的群數呢?一個評估方式是看看分 k 群時,各群平方距離的加總。例如:
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
# 各群平方距離的加總
def sum_squared_dist(data, centers, target):
# 第 i 群平方距離加總
def sum_square_dist(i):
p = data[np.where(target == i)]
return np.sum(cdist(p, [centers[i]]) ** 2)
sum_square_dist = np.frompyfunc(sum_square_dist, 1, 1)
k = centers.shape[0]
return np.sum(sum_square_dist(np.arange(0, k)))
# 分 k 群,求對應的各群平方距離加總
def k_sum_squared_dist(k, data):
def _k_sum_squared_dist(k):
kmeans = KMeans(n_clusters = k)
kmeans.fit(data)
centers = kmeans.cluster_centers_
target = kmeans.predict(data)
return sum_squared_dist(data, centers, target)
_k_sum_squared_dist = np.frompyfunc(_k_sum_squared_dist, 1, 1)
return _k_sum_squared_dist(k)
digits = load_digits()
k = np.arange(2, 25)
msds = k_sum_squared_dist(k, digits.data)
plt.plot(k, msds);
plt.show()
實際上,KMeans 有個 inertia_ 特性,可以求得各群平方距離加總,因此上例可以改為:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
# 分 k 群,求對應的各群平方距離加總
def k_sum_squared_dist(k, data):
def _k_sum_squared_dist(k):
kmeans = KMeans(n_clusters = k)
kmeans.fit(data)
return kmeans.inertia_
_k_sum_squared_dist = np.frompyfunc(_k_sum_squared_dist, 1, 1)
return _k_sum_squared_dist(k)
digits = load_digits()
k = np.arange(2, 25)
msds = k_sum_squared_dist(k, digits.data)
plt.plot(k, msds);
plt.show()
以上兩個範例都會顯示以下的結果:
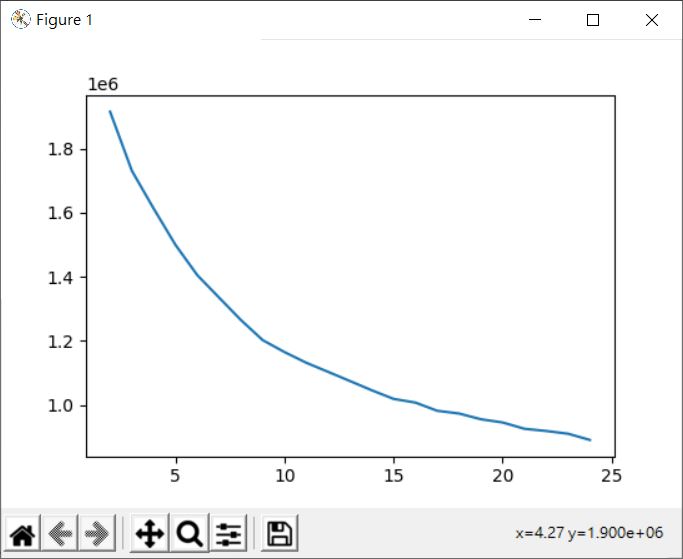
可以看出隨著 k 變大,各群平方距離加總變小,這是當然,畢竟分越多群的關係,透過這種圖形,是想要找出距離加總突然變和緩的 k 值,這表示增加更多的分群,令加總變小的效應是來自於持續縮減群體大小。
這個方式稱為手肘法(Elbow method),只不過這種方式,不太適合用於維度高的資料,因為每多一個維度,就會多一個機會讓距離增加,使得坡度緩和的部份變得不明顯,試著將數字資料降維看看:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
# 分 k 群,求對應的各群平方距離加總
def k_sum_squared_dist(k, data):
def _k_sum_squared_dist(k):
kmeans = KMeans(n_clusters = k)
kmeans.fit(data)
return kmeans.inertia_
_k_sum_squared_dist = np.frompyfunc(_k_sum_squared_dist, 1, 1)
return _k_sum_squared_dist(k)
digits = load_digits()
pca = PCA(2) # 將 64 維投影至 2 維
projected = pca.fit_transform(digits.data)
k = np.arange(2, 25)
msds = k_sum_squared_dist(k, projected)
plt.plot(k, msds);
plt.show()
這會顯示以下的結果:
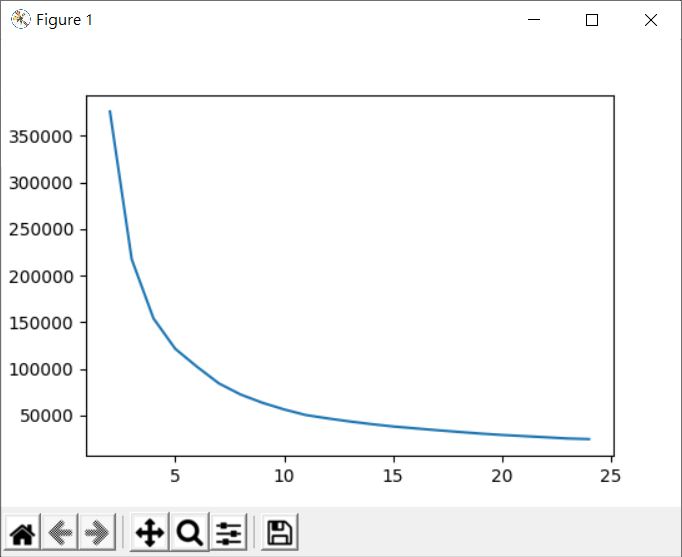
可以比較容易看出曲線中,以大致符合後段和緩部份往前畫一直線,大約會在 10 左右有快速抬昇的趨勢,這只是一種在 k 不清楚的情況下,有個嘗試的開始,實際上是不是適合的 k,還是要進一步的思考、嘗試與分析。
例如,上面的範例其實還涉及降維,這就有一個問題了,降為 2 維是好主意嗎?在〈主成分分析(二)〉中看過,在降為二維後畫出來的圖,其實群與群之間有很大的重疊性。
群與群之間的輪廓若是明顯,重疊部份理應較小,有一種稱為輪廓係數(Silhouette coefficient)的方式可以用來評估群與群間的輪廓,計算方式為 b * a / max(a, b),a 是群中各點間的平均距離,b 是某群中各點與最接近群中各點間的平均距離,輪廓係數越大,分群的品質就越好。
sklearn 的 sklearn.metrics.silhouette_score 可以用來計算輪廓係數,來看看降為 2 維時的樣子:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 分 k 群,求對應的各群平方距離加總
def k_sum_squared_dist(k, data):
def _k_sum_squared_dist(k):
kmeans = KMeans(n_clusters = k)
kmeans.fit(data)
# 輪廓係數
return silhouette_score(data, kmeans.labels_)
_k_sum_squared_dist = np.frompyfunc(_k_sum_squared_dist, 1, 1)
return _k_sum_squared_dist(k)
digits = load_digits()
pca = PCA(2) # 將 64 維投影至 3 維
projected = pca.fit_transform(digits.data)
k = np.arange(2, 25)
msds = k_sum_squared_dist(k, projected)
plt.plot(k, msds);
plt.show()
這會畫出以下的圖形:
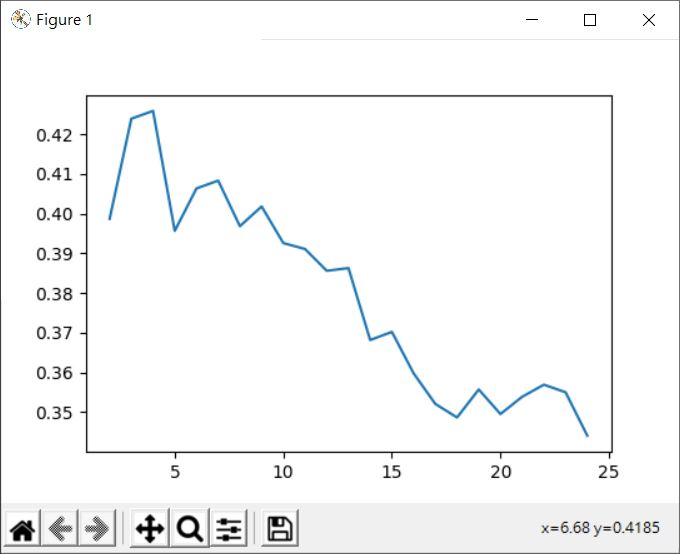
在降為 2 維的情況下,k 在 4 左右的輪廓係數最高,如果調整降維呢?有趣的是,試著調整維度,在大約 5 維以上之後,輪廓係數大致上都是在 k 為 10 左右最高,以下是 5 維時的情況:
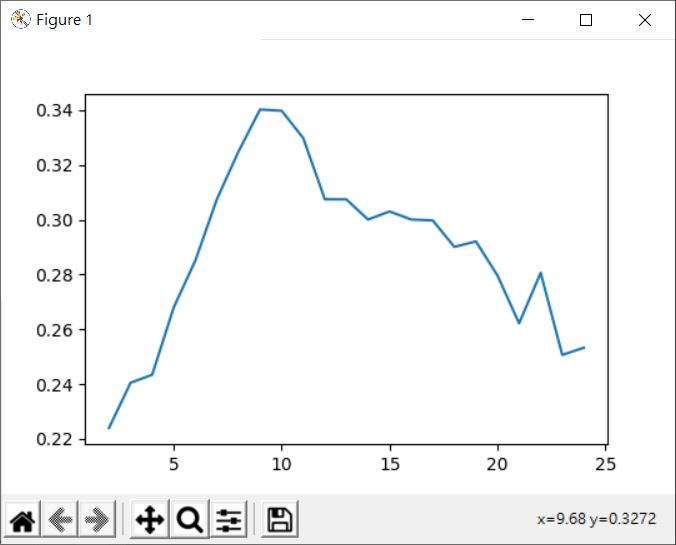
試著回頭去用手肘法對照一下:
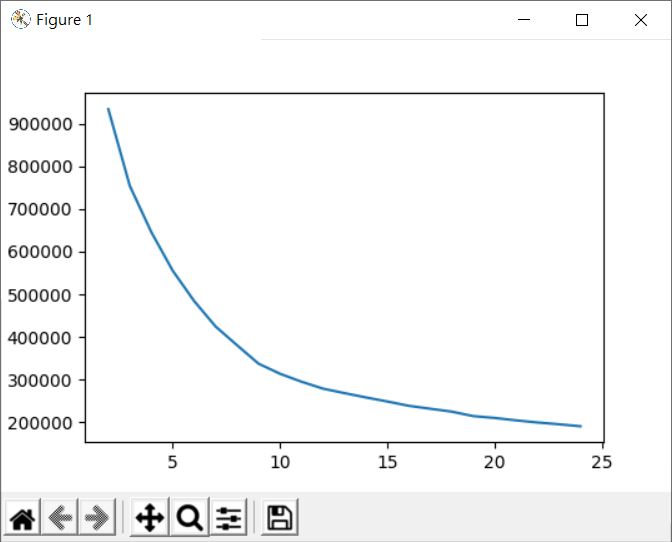
大致上也是可以選擇 k 為 10 左右呢!雖然有點事後諸葛(因為我知道會有 10 數字),不過輪廓係數雖然常用來評估分群,然而若遇到分群又要降維的情況下,用來尋找降維與分群的平衡點,似乎也是個不錯的方式。
在〈K-means 分群(一)〉簡介 K-means 分群原理時,是不是覺得分群時畫出一條線,成為兩個勢力範圍的感覺?這好像跟 Voronoi 空間劃分有點像?來看看這個範例吧!
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from scipy import spatial
k = 20
X, _ = make_blobs(n_samples = 500, centers = k, cluster_std = 0.8)
kmeans = KMeans(n_clusters = k) # 分群
kmeans.fit(X)
centers = kmeans.cluster_centers_ # 群心
y_kmeans = kmeans.predict(X) # 分群
# 以群心畫 Voronoi
vor = spatial.Voronoi(centers)
spatial.voronoi_plot_2d(vor)
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(
X[:,0], X[:,1],
c = y_kmeans, # 指定標記
edgecolor = 'none', # 無邊框
alpha = 0.5 # 不透明度
)
plt.show()
這會顯示以下的圖案:
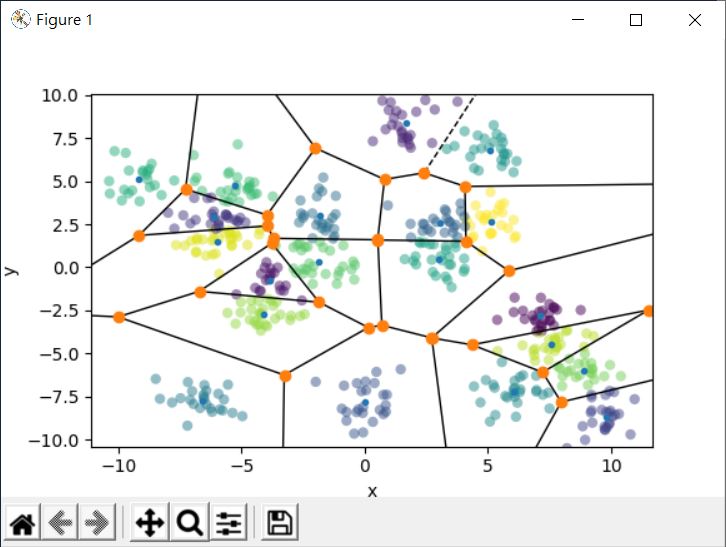
這指出了 K-means 的另一個應用,透過不同的 k 來分群,將分群後的資料透過一些方法分析(像是方才談到的手肘法、輪廓係數等),劃分出資料間的勢力範圍,從中思考資料會有哪些群聚趨勢,甚至進一步理解這些群聚趨勢代表著什麼意義?
就像〈K-means 分群(一)〉談到的,如果你從學歷差距、收入差距、年紀、居住縣市(經緯度、離首都的遠近)等資料,找出了某種群聚趨勢,那麼這各群代表了政治取向?消費習慣嗎?
群心勢力範圍內的資料屬於同一群,如果你瞭解 Voronoi,應該會意會到每個細胞的核,就是 K-means 的群心,資料會歸屬於哪一類,是看它離哪個群心近,也就是同一群資料中群心的影響最大,這表示可以使用群心來代表這一群的資訊,以上面的範例來說,原本 500 個點的資訊,被縮減為 20 個群心的資訊。
也就是說,K-means 應用之一就是壓縮資訊,例如應用之一,是用來減少色彩資訊。例如,彩色圖片具有 RGB,RGB 的資訊可以當成點資訊畫在三維空間中,相近的色彩在三維空間中,會有距離上的相近,若將之分群,以群心位置的 RGB 來作為同群的顏色,就可以減少色彩資訊,可能的應用之一是,在列印一張彩色圖片時,你只能使用 k 個顏色。
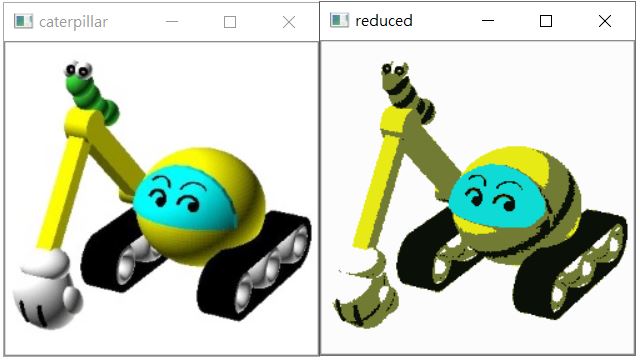
例如,以下範例可以指定要色彩的群數:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
import cv2
k = 5
img = cv2.imread('caterpillar.jpg')
X = img.copy().reshape((img.shape[0] * img.shape[1], 3))
kmeans = KMeans(n_clusters = k) # 分群
kmeans.fit(X)
centers = kmeans.cluster_centers_ # 群心
y_kmeans = kmeans.predict(X) # 分群
# 使用群心顏色填滿同一群
img2 = centers[y_kmeans].reshape(
(img.shape[0], img.shape[1], 3)).astype('uint8')
cv2.imshow('caterpillar', img)
cv2.imshow('reduced', img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
執行結果如下: