

在〈二維的 DataFrame〉中看過,可以透過 DataFrame 的 index 來建立或改變每一列資料的索引名稱,而在〈Pandas 輸入輸出〉中看過,read_csv 可以透過 index_col 來指定 CSV 中哪一行要作為索引。
DataFrame 實例的 set_index 方法也可以用來指定哪行要作為索引,例如:
import pandas as pd
scores = pd.DataFrame({
'座號' : ['No.01', 'No.02', 'No.03', 'No.04', 'No.05'],
'數學' : [90, 99, 92, 87, 85],
'英文' : [99, 87, 85, 67, 89],
'物理' : [100, 94, 76, 72, 67],
})
scores.set_index('座號', inplace = True)
print(scores)
在上例指定了 '座號' 該行資料作為索引,inplace 用來指定是否原地改變資料,若不指定,傳回的 DataFrame 實例才會是修改後的結果,執行的結果如下:
數學 英文 物理
座號
No.01 90 99 100
No.02 99 87 94
No.03 92 85 76
No.04 87 67 72
No.05 85 89 67
set_index 可以接受清單,也就是在必要的情況下,也可以指定多行來建立多重索引。例如:
import pandas as pd
scores = pd.DataFrame({
'座號' : ['No.01', 'No.02', 'No.03', 'No.04', 'No.05'],
'姓名' : ['Justin', 'Monica', 'Irene', 'Bush', 'Dora'],
'數學' : [90, 99, 92, 87, 85],
'英文' : [99, 87, 85, 67, 89],
'物理' : [100, 94, 76, 72, 67],
})
scores.set_index(['座號', '姓名'], inplace = True)
print(scores)
這會顯示以下的結果:
數學 英文 物理
座號 姓名
No.01 Justin 90 99 100
No.02 Monica 99 87 94
No.03 Irene 92 85 76
No.04 Bush 87 67 72
No.05 Dora 85 89 67
如果要指定多重索引取得某列,可以像是 scores.loc[('No.01', 'Justin')] 的方式,這會傳回 Series,上例若是僅指定 scores.loc['No.01'],會傳回 DataFrame,其中使用 '姓名' 作為索引行。
如果你的資料來源是 scores.csv,其中有以下資料:
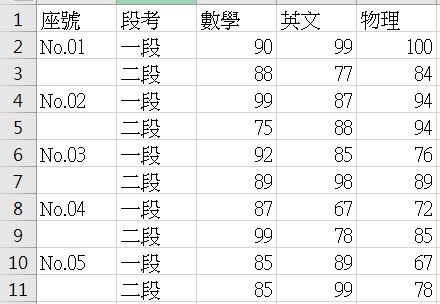
如果你直接讀入這個 CSV 的話,座號部份會有一些 NaN:
座號 段考 數學 英文 物理
0 No.01 一段 90 99 100
1 NaN 二段 88 77 84
2 No.02 一段 99 87 94
3 NaN 二段 75 88 94
4 No.03 一段 92 85 76
5 NaN 二段 89 98 89
6 No.04 一段 87 67 72
7 NaN 二段 99 78 85
8 No.05 一段 85 89 67
9 NaN 二段 85 99 78
DataFrame 有一些可以處理 NaN 的方法,像是 dropna 可以直接丟棄 NaN 的行或列,fillna 可以為 NaN 填值,這邊要使用 fillna,在軸 0 方向用 NaN 前一個值來補上:
import pandas as pd
scores = pd.read_csv('scores.csv')
scores.fillna(method = 'ffill', axis = 0, inplace = True)
print(scores)
這會顯示以下結果:
座號 段考 數學 英文 物理
0 No.01 一段 90 99 100
1 No.01 二段 88 77 84
2 No.02 一段 99 87 94
3 No.02 二段 75 88 94
4 No.03 一段 92 85 76
5 No.03 二段 89 98 89
6 No.04 一段 87 67 72
7 No.04 二段 99 78 85
8 No.05 一段 85 89 67
9 No.05 二段 85 99 78
接下來的問題是,如果為這個 DataFrame 設定索引,以便能透過 loc 來指定取得某列?例如 No.04 的第二次段考分數呢?單獨指定 '座號' 或 段考,都不能達到這個要求,你必須同時指定,例如:
import pandas as pd
scores = pd.read_csv('scores.csv')
scores.fillna(method = 'ffill', axis = 0, inplace = True)
scores.set_index(['座號', '段考'], inplace = True)
print(scores)
print(scores.loc[('No.04', '二段')])
這會顯示以下的結果:
數學 英文 物理
座號 段考
No.01 一段 90 99 100
二段 88 77 84
No.02 一段 99 87 94
二段 75 88 94
No.03 一段 92 85 76
二段 89 98 89
No.04 一段 87 67 72
二段 99 78 85
No.05 一段 85 89 67
二段 85 99 78
數學 99
英文 78
物理 85
Name: (No.04, 二段), dtype: int64
有點難以理解嗎?其實資料來源 scores.csv 中的資料,應該要分為兩張資料表,一張記錄第一次段考,另一張記錄第二次段考,例如,第一張資料表應該長得像這樣:
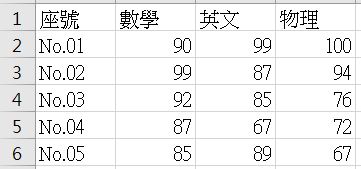
也就是說,資料來源 scores.csv 是兩張資料表合在一起了:
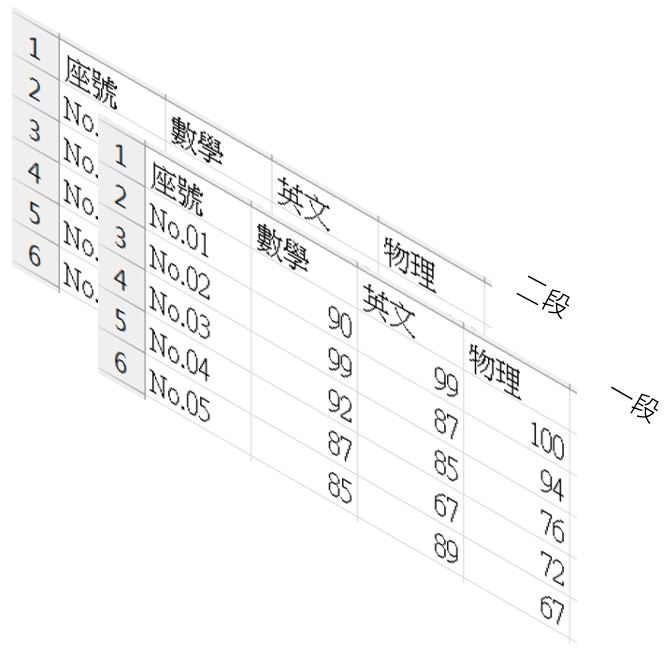
這看來像是三維的資料了,若要表示三維的資料,在過去會使用 Pandas 的 Panel,不過它已經被標為棄用了(Deprecated)了,如果使用的話,會出現以下訊息:
DeprecationWarning: Panel is deprecated and will be removed in a future version. The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method. Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/. Pandas provides a .to_xarray() method to help automate this conversion.
也就是說,其中建議透過 DataFrame 與 MultiIndex,也就是多重索引的方式來表示三維資料。
這也表示,若你有多個 DataFrame,各表示二維的資料,例如各表示第一次與第二次段考的成績,也可以合併為一個 DataFrame,並設定多重索引。例如:
import pandas as pd
scores1 = pd.DataFrame({
'座號' : ['No.01', 'No.02', 'No.03', 'No.04', 'No.05'],
'數學' : [90, 99, 92, 87, 85],
'英文' : [99, 87, 85, 67, 89],
'物理' : [100, 94, 76, 72, 67]
})
scores2 = pd.DataFrame({
'座號' : ['No.01', 'No.02', 'No.03', 'No.04', 'No.05'],
'數學' : [88, 75, 89, 99, 85],
'英文' : [77, 88, 98, 78, 99],
'物理' : [84, 94, 89, 85, 78]
})
# 串接 DataFrame
scores = pd.concat([scores1, scores2])
scores.sort_values('座號', inplace = True)
# 加入新的一行
scores['段考'] = ['一段', '二段'] * 5
# 多重索引
scores.set_index(['座號', '段考'], inplace = True)
print(scores)
有關於 DataFrame 的串接、合併等操作,可以進一步參考〈Merge, join, concatenate and compare〉,有關於索引方面的操作,可以進一步參考〈MultiIndex / advanced indexing〉。