在〈多層感知器(一)〉使用了兩個感知器,先將資料各分為兩類,並透過最後一個感知器,將資料再次分類,從而達到想要的效果,不過,並不是每次都可以這麼組合出來。
在〈多層感知器(二)〉中談到了,如何以矩陣的方式,也就是 a(W(2) @ a(W(1) @ x + b(1)) + b(2)) 這種形式,表達出多層感知器的結果,若有更多層、更多感知器,這樣的表示方式下,就是矩陣大小以及相乘的層次問題,如果你試著去瞭解多層感知器的推導過程,也會看到這種形式,可以用來推導出權重與偏差等的更新方式。
若要用現成的程式庫,sklearn 的 sklearn.neural_network.MLPClassifier 提供了多層感知器的實作(MLP 就是 Multi-layer Perceptron),例如,現在有個 height_waist3.csv,內容是身高、腰圍與標記,0 表示適中體型,1 表示太胖或太瘦:
171,110,1
157,90,1
164,115,1
182,75,0
160,103,1
199,68,1
152,103,1
179,67,1
164,83,0
167,102,1
167,77,0
165,87,0
...略
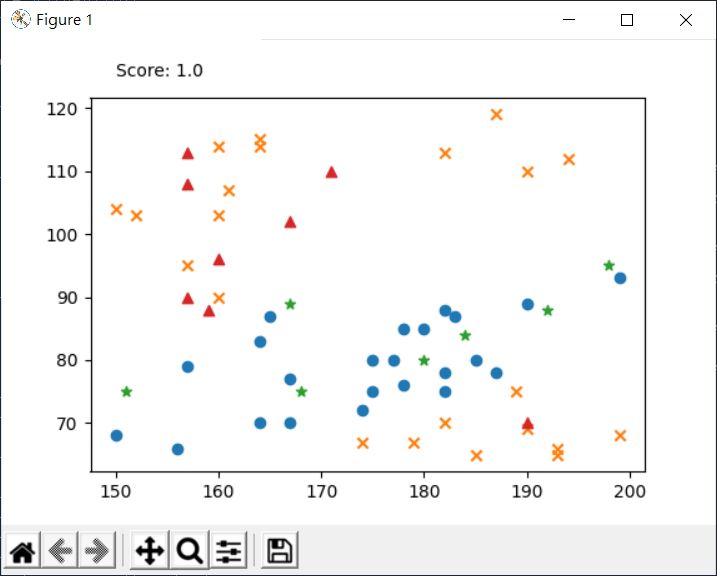
透過底下這個簡單程式,就可以實現〈多層感知器(一)〉中的效果:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
data = np.loadtxt('height_waist3.csv', delimiter=',')
height_waist = data[:,0:2]
label = data[:,2]
# 透過 train_test_split 來分出學習與測試資料
hw_train, hw_test, lb_train, lb_test = train_test_split(
height_waist, label, stratify=label, random_state = 1
)
# 顯示學習資料
plt.scatter(hw_train[lb_train == 0, 0], hw_train[lb_train == 0, 1], marker = 'o')
plt.scatter(hw_train[lb_train == 1, 0], hw_train[lb_train == 1, 1], marker = 'x')
# 使用 MLPClassifier 來學習
classifier = MLPClassifier(
activation = 'logistic', # 二元分類的激勵函式
solver = 'lbfgs', # 權重最佳化的演算法
hidden_layer_sizes = (30,), # 隱藏層的感知器數量
max_iter = 400 # 更新模型參數的上限次數
)
classifier.fit(hw_train, lb_train)
# 用測試資料預測
pred = classifier.predict(hw_test)
plt.scatter(hw_test[pred == 0, 0], hw_test[pred == 0, 1], marker = '*')
plt.scatter(hw_test[pred == 1, 0], hw_test[pred == 1, 1], marker = '^')
# 評估
plt.text(150, 125,
"Score: " + str(classifier.score(hw_test, lb_test)))
plt.show()
MLPClassifier 可以指定許多參數,這邊只列出了基本的幾個,首先,在〈多層感知器(二)〉談到的激勵函式是 0 或 1 的輸出,這稱為單位階躍函式(Heaviside step function),由於輸出僅 0 或 1,運用了單位階躍函式作為激勵函式的感知器,就像是在建立 AND、OR、XOR、NAND 等邏輯閘,在多層感知器的情況下,就是將這些邏輯閘組合起來。
實際上,電腦就是這麼組合起來的,為了要能組合出電腦,以邏輯閘逐層組合出各種元件,從這方面來想像先前感知器的組合為何能夠運作,是一種理解多層感知器的方式。
不過,在多層感知器的推導過程中,激勵函式會參與微分的過程,目的是用於提供回饋以修正權重、偏差,單位階躍函式微分後是 0,無法提供回饋,因此不適合作為激勵函式。
如果能夠使用不單只是輸出 0 或 1 的激勵函式呢?理論上,可以組合出任何形式的函式,也就是可以用更複雜的函式來建立分類的邊界。
激勵函數的選擇,除了是否易於微分的考量外,還有梯度消失、梯度爆炸、收斂速度、擬合度等各方面的考量,因此你會在維基百科〈激勵函數〉中看到許多的激勵函數。
這邊範例使用的 'logistic' 就是表示使用邏輯函式,因其形狀類似 S,被歸為 Sigmoid 函式或 S 函式,易於微分,來看看它繪製出來的圖是介於 0 到 1 的輸出:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-6, 6, 1000)
y = 1 / (1 + np.exp(-x))
plt.plot(np.linspace(-6, 6, 1000), y)
plt.show()
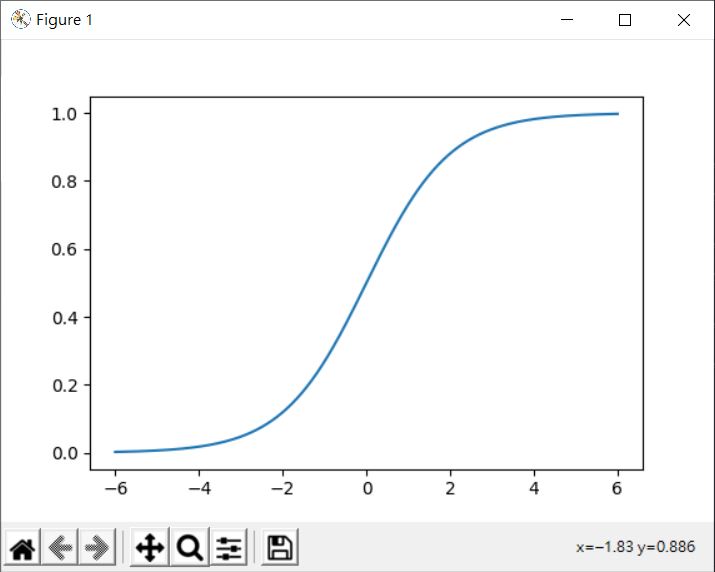
邏輯函式會將上一層的訊號轉換為 0 到 1 間的連續輸出,接近 1 的輸出,表示對下一層對應的權重影響越大,越接近 0 的輸出,越不會影響下一層對應的權重,也就是說,邏輯函式會讓重要的資訊有較大的輸出值,不重要的資訊有較小的輸出值。
另外一個常用的是線性整流函式(Rectified Linear Unit, ReLU),也是易於微分:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-6, 6, 1000)
y = np.where(x > 0, x, 0)
plt.plot(np.linspace(-6, 6, 1000), y)
plt.show()
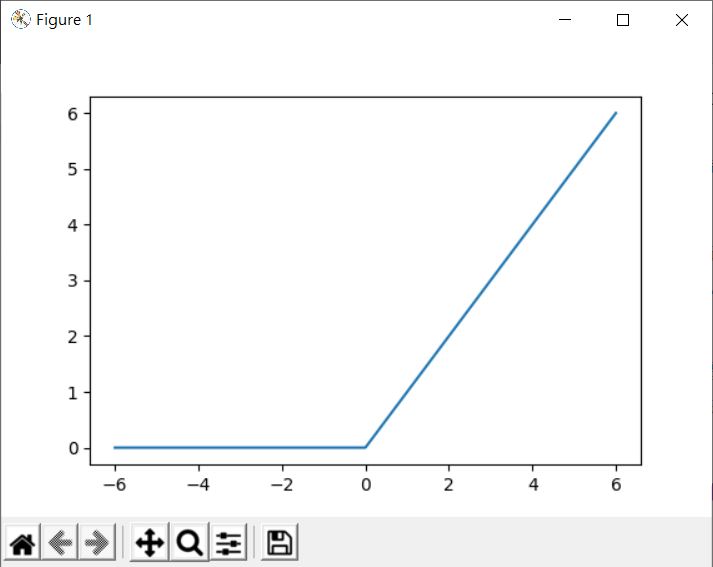
這個激勵函式是 MLPClassifier 的預設值,對於不大於 0 的輸入,輸出會是 0,大於 0 的數則直接輸出,這就像是在設定閥值,上一層的輸出只有在大於 0 的情況下,輸出值才會完全作為下一層的輸入,否則就不會影響(因為 0 乘於下一層輸入對應的權重,結果該項為 0,相當於該權重不發揮作用)。
solver 用來設定權重更新時,要採用哪一種方式選擇學習資料。舉例來說,如果你試著去理解多重感知器的推導過程,應該會接觸到梯度下降法(Gradient descent),簡單來說,就是如何尋找最小值的一種方式,如果目標函式只是個凹口向上的拋物線,這種方式基本上是沒問題。
然而,如果目標函式是個上下起伏多次的曲線呢?學習時資料沒選對,找到的最小值,可能只是某個谷的最小值,也就是區域最小值,解決這種問題的方式之一,就是隨機選擇資料,以這種想法為出發點,就有了隨機梯度下降法(Stochastic gradient descent),solver 若設為 'sgd',就是採用這個方式。
類似地,'adam'(預設)、'lbfgs' 代表尋找最小值時不同的演算方式,solver 的設定會影響結果與運算效率,例如是否陷入區域最小值、無法收歛,或者是耗費過多的運算時間等,可能都與 solver 的設定有關。
在 solver 的使用時,學習率的設定很重要,而 'adam' 對多數需求而言,是不錯的開始,它會為每個參數指定不同的學習率,並在過程中自動調整學習率,這也是為何它會被作為預設的原因。
(在《Deep Learning|用 Python 進行深度學習的基礎理論實作》第六章,有討論 sgd、adam 等的不同,可以參考看看。)
由於這邊的資料量少,根據文件,適用 'lbfgs' 演算;隱藏層的感知器數量,可以透過 hidden_layer_sizes 設定,如果需要多個隱藏層,就增加 tuple 的維度來設定;max_iter 用來決定重複迭代學習資料的上限值,也就是學習過程無法收斂(由 tol 參數控制),最多迭代的次數,若無法收斂可以提高次數,然而當然也會耗費更多時間運算,每迭代一次稱為一輪(epoch),也就是一個訓練週期。
在這邊 hidden_layer_sizes 與 max_iter 是透過幾次試驗,看看 score 方法評估結果調整出來的,根據〈How to Configure the Number of Layers and Nodes in a Neural Network〉。
在〈多層感知器(二)〉中談過,感知器會接上激勵函數,激勵函數其實就是在進行空間轉換,同一層每多一個感知器,就表示原資料多了一個被轉換後的空間,簡單而言,就是試著抽取出新的特徵,而每多一個隱藏層,就是多一次空間轉換的串接,從數學函數來看,就是在多一次函數合成,就程式設計來看,就像是在試著建立更多的條件組合。
同一層中會想要有更多感知器,比較像是在猜想能不能先抽取出個別特徵,例如,手寫文字的辨識時,猜想可以先將圖片分為幾個區域,看看該區域蓋的筆劃,先試著分類;每多一層,則是在猜想,這些分類透過適當的合成,是不是能合成出適當的函數或適當的條件組合,畫出合適的決策邊界,從而能提高預測的準確度呢?
類似這類的猜想,可能會是增加感知器或隱藏層數量的理由,當然,多層感知器很大程度上就像個黑盒子,感知器之間的關係,層與層之間的意義,基本上只有多層感知器本身才知道,整個神經網路其實就是個複雜的數學函數,函數中的參數會藉由大量資料來調整,人們想理解其中的意義往往極為困難的任務。
人們能做的,是透過感知器的數量、層數、各種超參數,試著調整數學函數的組成方式,提供大量的資料進行訓練,看看預測結果的評分是否合乎需求,這只能從多試驗、評估、深入理解資料、演算法等各方面來下手…XD
來看看執行結果: