

雖然涉及一些數學運算,不過,你應該試著去理解過感知器的原理,如果你暫時沒那時間,或者是曾經試著從公式去理解而不得其門而入,以下來提供另一種理解方式。
在〈多層感知器(一)〉中使用了三個感知器,如果將三個感知器的 coef_ 與 intercept_ 顯示出來會得到:
print(p1.coef_, p1.intercept_) # [[-60. 107.]] [0.]
print(p2.coef_, p2.intercept_) # [[ 321. -800.]] [-1.]
print(p3.coef_, p3.intercept_) # [[2. 2.]] [-1.]
在〈分類與感知器〉中提過,coef_ 是感知器的權重向量(在直線的情況下,也可以理為直線的法向量),而 intercept_ 其實是感知器的偏差(bias)(在直線的情況下,也可以理為直線的截距)。
對於一個感知器,它的輸出其實是透過 W . X + b,要輸出 1 或 0,W 表示權重向量,X 是變數值的向量,b 是偏差值,如果 W . X + b > 0 輸出 1,W . X + b <= 0 輸出 0。
既然〈多層感知器(一)〉中已經訓練好三個感知器,那麼就直接用它的權重與偏差吧!對於 p1、p2 感知器可以寫成:
import numpy as np
import matplotlib.pyplot as plt
def a(x):
return 1 if x > 0 else 0
def p1_predict(height, waist):
w1 = np.array([-60, 107])
b1 = 0
return a(np.dot(w1, [height, waist]) + b1)
def p2_predict(height, waist):
w2 = np.array([321, -800])
b2 = -1
return a(np.dot(w2, [height, waist]) + b2)
height = 165
waist = 85
print(p1_predict(height, waist)) # 顯示 0
print(p2_predict(height, waist)) # 顯示 0
現在 p1、p2 各輸出為 0,接著將輸出接至 p3
def p3_predict(p1_o, p2_o):
w3 = np.array([2, 2])
b3 = -1
return a(np.dot(w3, [p1_o, p2_o]) + b3)
# 顯示 0
print(
p3_predict(
p1_predict(height, waist),
p2_predict(height, waist)
)
)
你可以試試不同的 height、waist,看看 p3_predict 最後輸出結果是否符合分類;其實以上的過程,可以透過矩陣運算組合在一起:
import numpy as np
import matplotlib.pyplot as plt
def a(x):
return np.where(x > 0, 1, 0)
def p1p2_predict(height, waist):
# 建立矩陣
w = np.array([
[-60, 107],
[321, -800]
])
b = np.array([0, -1])
# @ 是矩陣相乘
return a(w @ [height, waist] + b)
def p3_predict(p1p2_o):
w3 = np.array([2, 2])
b3 = -1
return a(np.dot(w3, p1p2_o) + b3)
height = 165
waist = 85
print(
p3_predict(
p1p2_predict(height, waist)
)
)
為了將一般化,來為這些感知器、權重、偏差等取名稱好了,為此編好號碼:
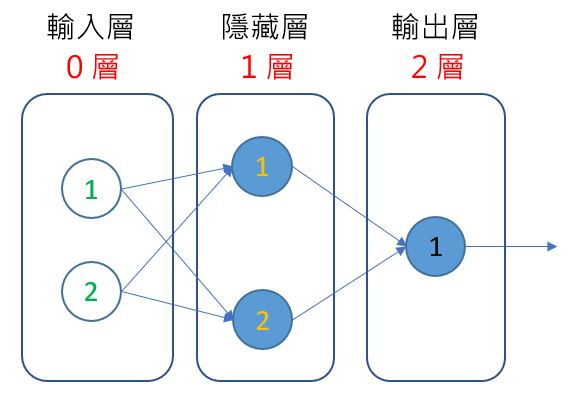
每一層的感知器,是由上往下編號,對於第 1 層的 1 號感知器,權重為 [-60, 107],偏差為 0,給予名稱 [w111, w112],以及 b11,也就是說上標表示哪一層,下標表示哪一號感知器接收上一層哪一個輸入,例如 1 層 1 號感知器需要就是:
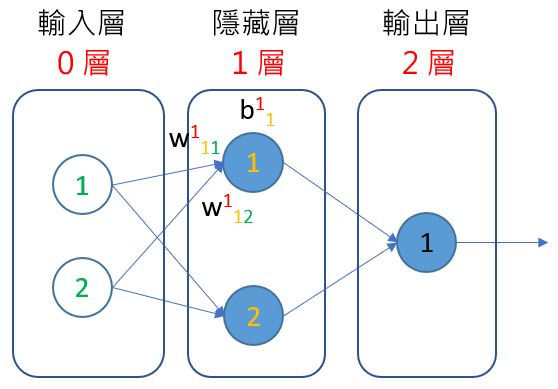
類似地,1 層 2 號感知器需要就是:
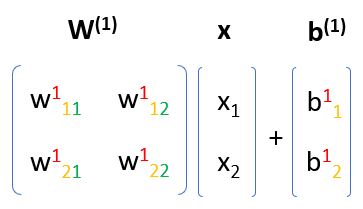
那麼方才的矩陣運算,就可以表示為 W(1) @ x + b(1):
方才程式運算時的 a 函式,將運算結果轉為 0 或 1,稱為激勵函式,之所以這麼稱呼,是因為它控制了什麼樣的值,可以輸出 1,進一步激發下一個感知器,為什麼需要這個激勵函式呢?一個感知器的輸出是 W . X + b,可以處理線性的問題,將多個感知器的輸出直接作為其他感知器的輸入,最後組合出來的輸出,其實也會是 W . X + b 這樣的形式,還是只能處理線性的問題。
多個感知器的輸出若有了激勵函式的轉換,再作為其他感知器的輸入,組合出來的形式就有可能是 W . X + b 以外的形式,根據感知器的數量、激勵函式的選擇以及層數的不同,組合後的形式會是千變萬化,也就是說,你的分類線不再是直線,而會是各種可能的形狀,可以用來處理非線性的分類問題了。
從另一個角度來看,激勵函式是在改變特徵空間,將空間中的一組特徵映射至另一個空間成為另一組特徵,然後在該空間中尋找映射後特徵的線性邊界。
聽來很像是〈多元線性迴歸(二)〉中談過的 PolynomialFeatures,轉換後的特徵值可以更好地被線性模型 LinearRegression 擬合?某些程度上是類似的概念,只不過各種感知器的數量、激勵函式的選擇以及層數的不同下,各種特徵空間轉換的組合更為複雜,更加難以想像。
這就是為什麼,這邊要透過三個感知器來組合,因為比較容易理解激勵函式的作用,簡單來說,原本一個感知器只能有一條直線進行分類,透過激勵函式的轉換以及感知器的組合,就像是結合了兩條分類直線,來達到非線性分類的需求。
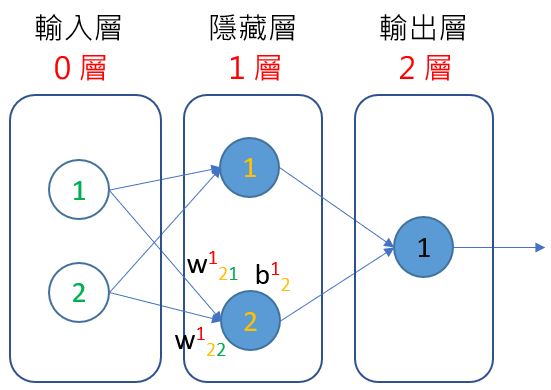
將激勵函式組合上去,就成為 a(W(1) * x + b(1)),就目前來說,結果會是個 1x2 矩陣,會是 2 層 1 號感知器的輸入,而對於 2 層 1 號感知器需要的是:
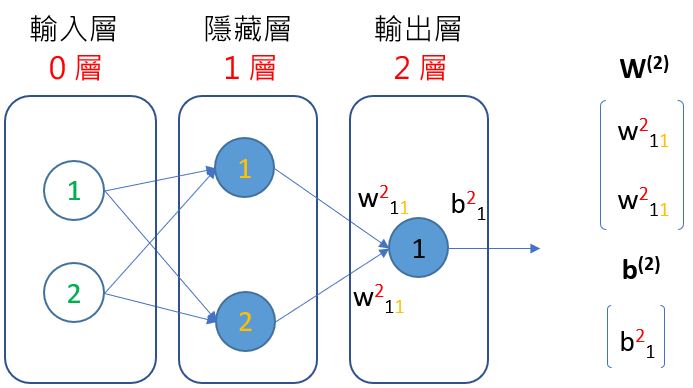
根據上圖的標示,最後的輸出結果會是 a(W(2) @ a(W(1) @ x + b(1)) + b(2)),可以看到,若有更多層、更多感知器,這樣的表示方式下,就是矩陣大小以及相乘的層次問題。
另一方面,透過一些數學推導過程,權重矩陣與偏差矩陣的實際值,可以從資料中學習得到,有興趣瞭解推導過程,就自行找相關的理論書或文件…XD